
|
# |

|
Hey # |

|
I’m Dan McKinley. That’s me in the hole. It’s a metaphor. # |
|
I work for a company called Mailchimp, or Mailkimp if you listen to podcasts. I was an early employee at Etsy, and that was a formative experience for me, so I’ll refer to my time there a lot. But I’ve worked for a few other places since. # |

|
I’ve worked at big companies and at smaller ones, and at my own tiny startups. I’ve noticed a few things. Big companies can have a branded way of doing engineering. For example, “The Etsy Way” of doing engineering became a thing. Living inside of that box where your needs are met and questions are answered can spoil you somewhat. But I’ve also been in situations where “the way engineering is done” is actively being figured out, or in periods of transition. And in those situations I’ve had to ponder a couple of questions. # |

|
First, how do you pick the tools you’re going to use to get your work done? # |

|
Another question I care about is: how do you make developers happy? This matters to me, as a developer. I would like to be happy, if possible. # |

|
If you go up to a developer and say, “hey, what would make you happy?” you often get highly specific answers. “I would be happy if I could write Clojure at work,” they’ll say, “so you should let me do my work in Clojure.” I don’t discount that when they do this, developers are genuinely describing some kind of endorphin-rich experience they have had at some point. However, I am skeptical that the state that they’re describing is the highest level of spiritual attainment possible. # |

|
But I, too, was once like this. # |
|
Etsy for example, early on, was a big ball of PHP spaghetti. It was written by someone that was unfortunately learning PHP as he was writing it. I spent several years just trying to avoid dealing with it. At one point I tried building Scala services that talked to MongoDB. I thought this would result in better infrastructure, solve all of my productivity problems, and would make me happy. But no part of that turned out to be the case. The embarrassing wreckage of this period is still on the internet, you can go find it and make fun of me. And Etsy employees still give me shit about it, with good cause. # |
|
When I had my own startup last, I did use Clojure. I don’t think that Clojure is the reason, but I should disclaim here that that startup is no longer in business. Anyway I want to offer these anecdotes as my non-luddite bona fides. I am not someone that has never experienced the joy of functional programming. You don’t need to @ me to talk about Scala or Haskell. You certainly don’t need to do that with a rebuttal taking all of this extremely personally, even though I haven’t even mentioned you or those languages at all, Steve. # |
|
But anyway, despite that, I’m mostly not a tool-obsessed engineer. My other talks are barely even about engineering. # |
|
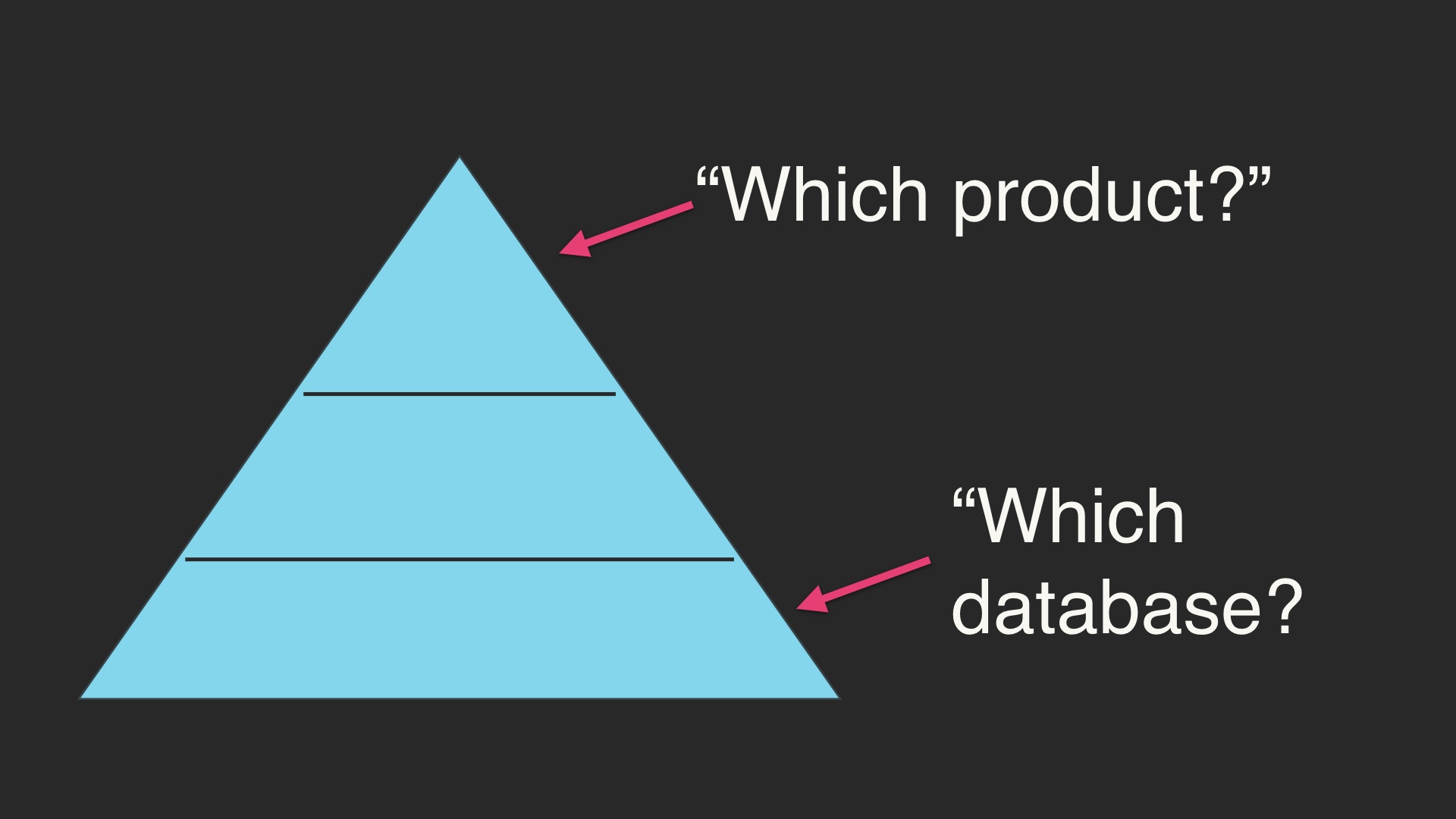
I don’t think I’ve become that way because I’ve gotten old and cranky. Although I am certainly those things, I think I’ve gotten perspective on this by summiting Maslow’s hierarchy at some point in my past. Maslow’s hierarchy, briefly, is the idea that you have to satisfy your more basic needs before higher levels of intellectual fulfillment are possible. You can’t do poetry if you’re worried about what you’re going to eat today. # |
|
We can look to the case of Siegfried Sassoon and ponder whether this is the case or not for poetry, but I think it's mostly true in software. You can’t worry about the big picture and ask intelligent questions about the direction of the product if you’re busy arguing about which database or alerting system to use. I’ve been pretty lucky to have been in situations where those basic needs were fulfilled. And I want to help get others to this state. # |

|
An important step in getting to that state is realizing that attention is precious. Humans have a finite amount of capacity for sweating details. # |

|
My friend Andrew wears the same brand of black shirt every day. He thinks that if he conserves the brainpower it would take to pick something to wear, he’ll bank it and be able to use it later for something else. I don’t know if this makes sense for fashion or what have you, but I really think there is something to this. # |

|
I like to think about it like this. Let’s say that we all get a limited number of innovation tokens to spend. This is a purely fictional construct I just made up, and my ICO goes on sale next week. These represent our limited capacity to do something creative, or weird, or hard. We really don’t have that many of these to allocate. Early on in a company’s life, we get like maybe three. Not too many more than that. # |
|
So what’s your company trying to do? Well, Etsy, where I used to work, used to make the claim that it was trying to reshape the entire world economy. Now I don’t know the extent to which we should take tech company missions seriously. I am beginning to suspect that we should not take them seriously at all. But let’s be naive for a minute, and consider the implications that would result if they really wanted to do this. # |
|
Reshaping the entire world economy sounds like a big job. And that probably costs at least one of your tokens. # |
|
A company I worked at after Etsy is trying to “increase the GDP of the internet.” # |
|
Again, that sounds like a pretty complicated thing to be doing. We probably have to spend at least one of our tokens on that. Maybe two. Maybe all of them! # |
|
If you think about innovation as a scarce resource, it starts to make less sense to also be on the front lines of innovating on databases. Or on programming paradigms. The point isn’t that these things can’t work. Of course they can work. And there are many examples of them actually working. But software that’s been around longer tends to need less care and feeding than software that just came out. # |

|
To get at the reason for that I want to talk about the philosophy of knowledge a little bit. What can we know about a piece of technology? This is not actually a frivolous question. It’s really important. # |

|
I hate Donald Rumsfeld, and I hope he fries. But he’s associated with the following, which is thoroughly relevant to our subject. So I feel like I have to acknowledge his demonic presence long enough to distance myself from him. # |

|
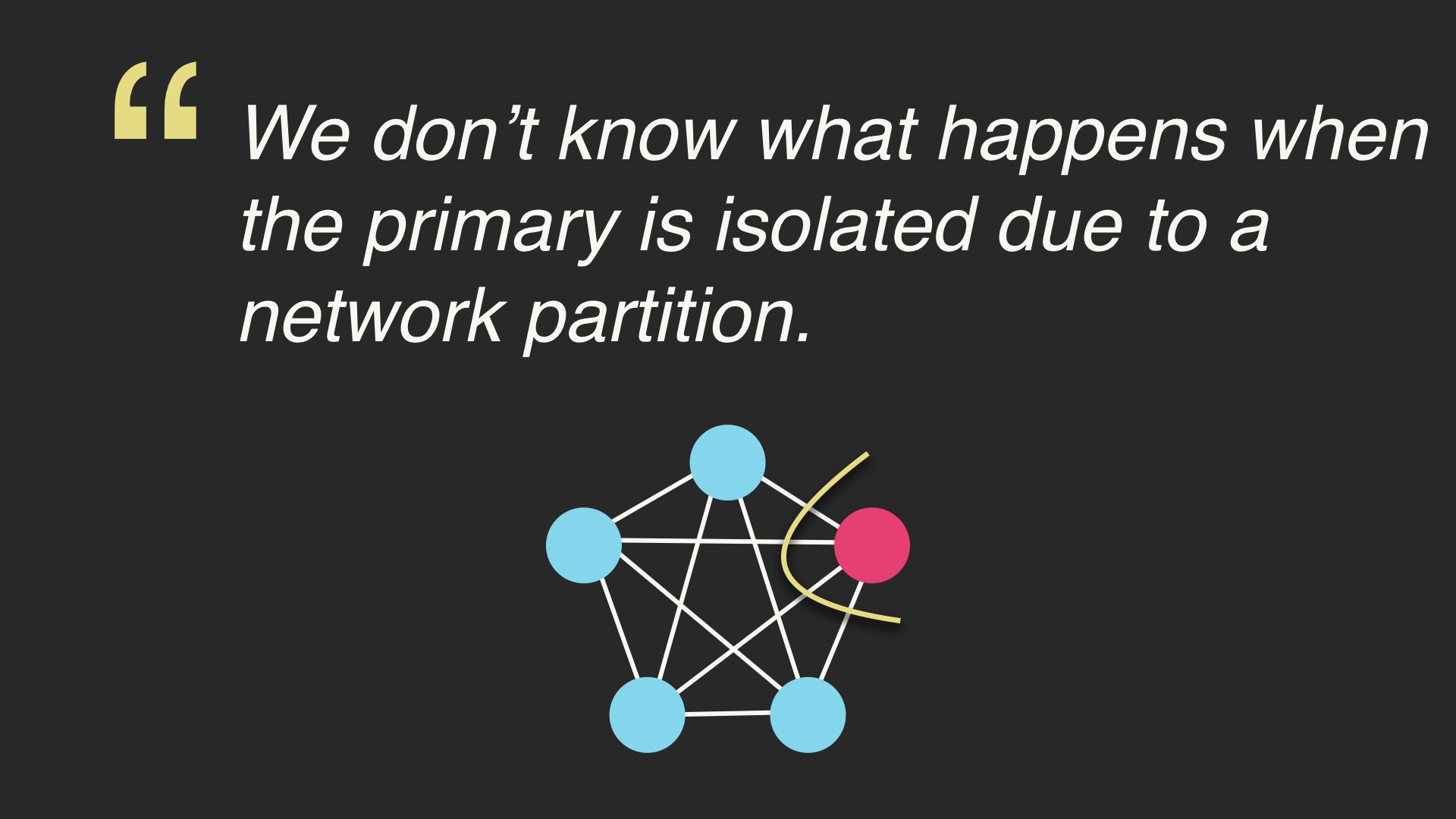
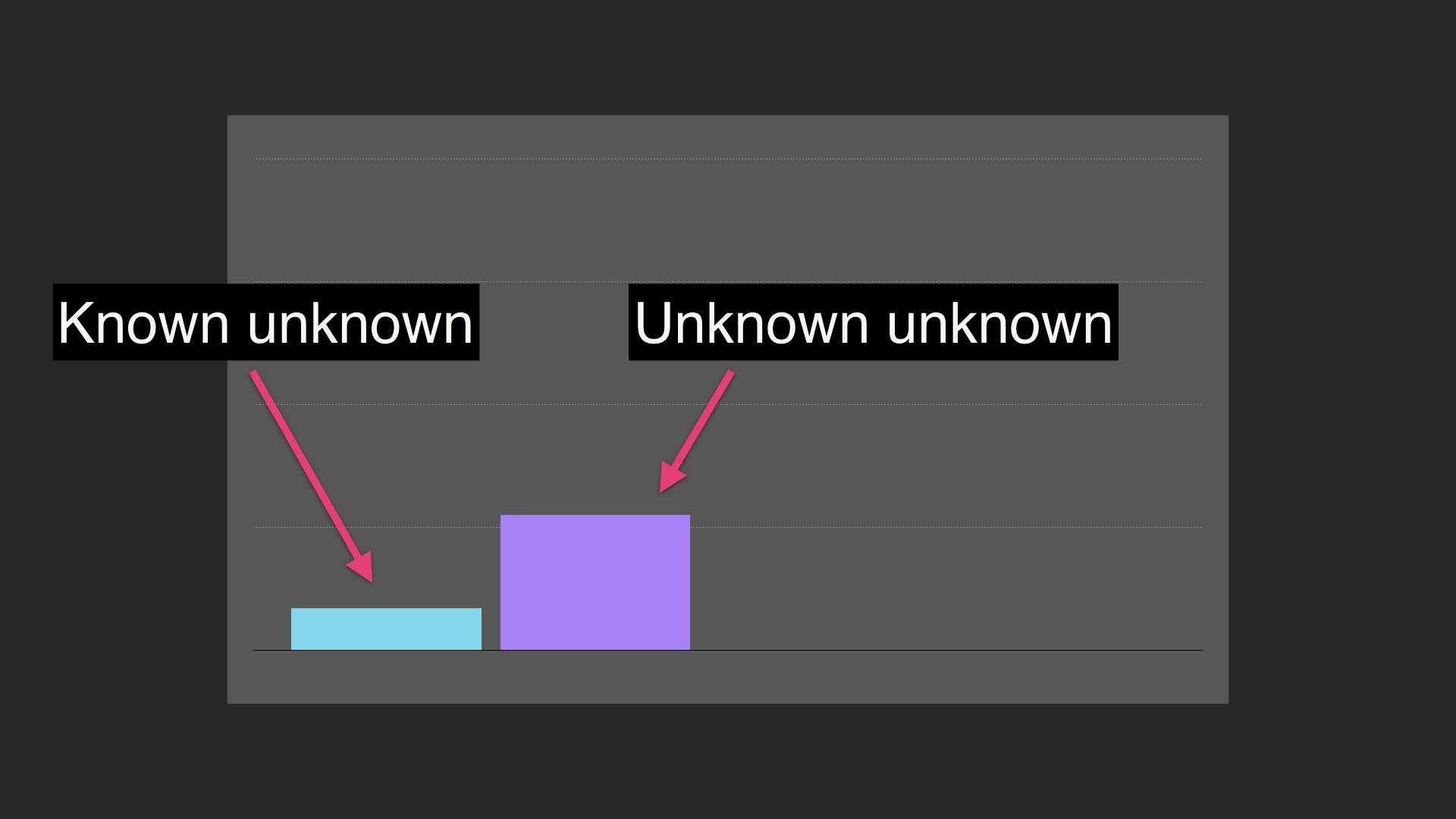
When we don’t know something, there are really two different categories that that lack of knowledge can be in. There are known unknowns, that is, things that we know that we don’t know. And there are unknown unknowns, things that we don’t know and that we don’t know that we don’t know. # |
|
This applies in technology. This is an example of a known unknown. For a given database, we might not know what happens when a network partition occurs. But we know that a network partition is possible. Since we know that this is possible, we can test for this. Or we can just cross our fingers and hope that it doesn’t happen. Either way, we are informed about the possibility. # |

|
There are also unknown unknowns in technology. This is a random example I saw a while back. This person spent four months trying to figure out why he was getting GC pauses, and it turned out to be because he was writing stats to a file. He had no idea that that was a thing that could happen, but it was. Many bugs in software are like that. We don’t know they’re there, and we don’t even really know we should be on the lookout for them. They’re unknown unknowns. # |
|
Now, it’s important to realize that both categories are present in all software. Software that’s 10 years old generally comes with a JIRA instance full of tickets describing broken stuff that nobody’s ever going to fix. And then there are always bugs that nobody knows about, even in software that’s been around forever. # |
|
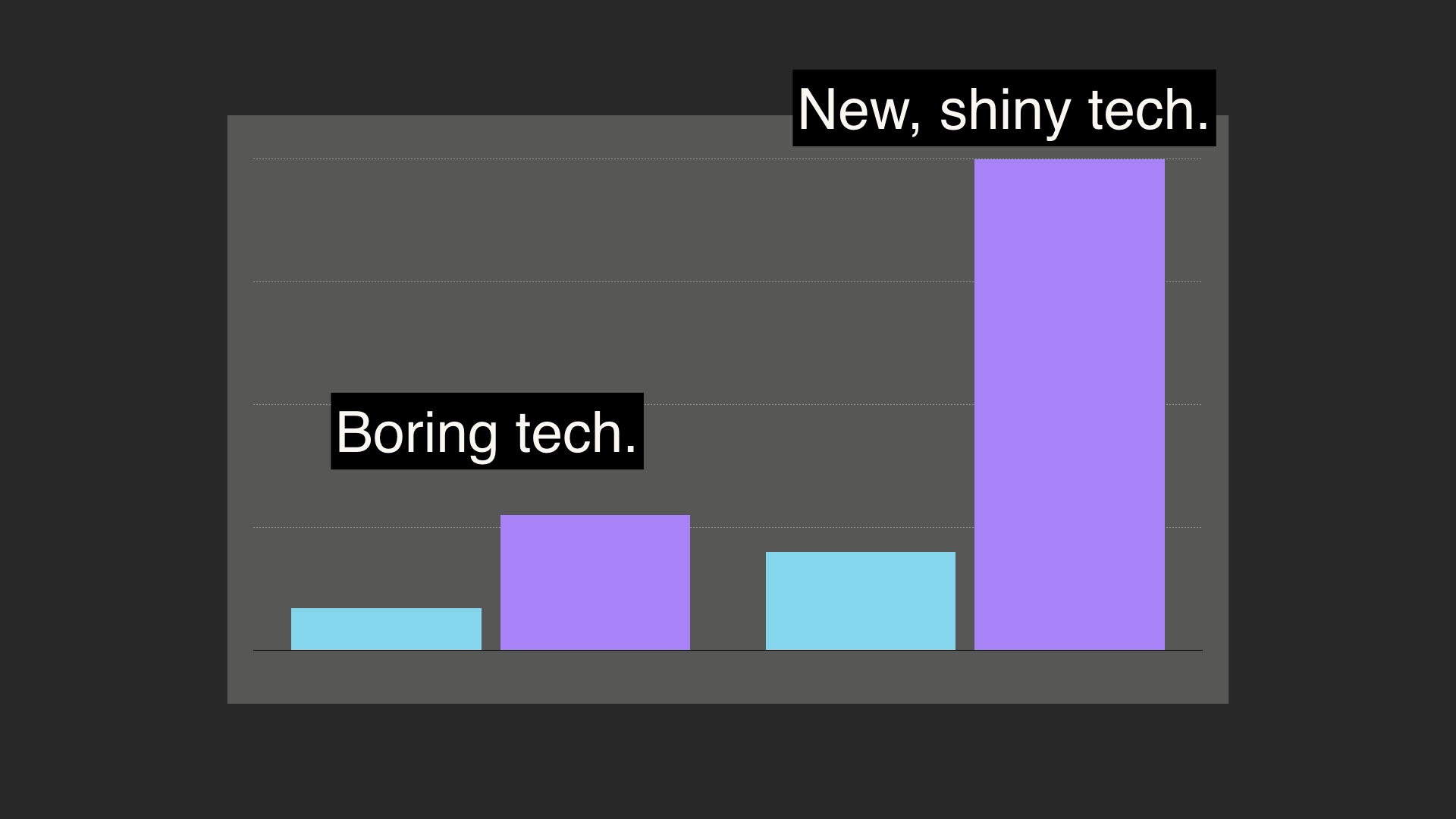
But it’d be wrong to say that all technology is therefore equivalent. New technology has a larger cardinality for both of these sets. New tech typically has more known unknowns, and many more unknown unknowns. And this is really important. # |

|
I chose “boring technology” as the pithy SEO-friendly title for this content, and I regret it most days. It’s kind of distracting. “Boring sounds bad, why is he saying it’s good?” Et cetera. It’s a real shitshow. But what I’m aiming for there is not technology that’s “boring” the way CSPAN is boring. I mean that it’s boring in the sense that it’s well understood. It’s bad, but you know why it’s bad. You can list all of the main ways it will let you down. # |

|
So, ok, all you have to do is use Postgres, and you’re all set, right? Well, no. Unfortunately the combination of things that you choose also matters. # |
|
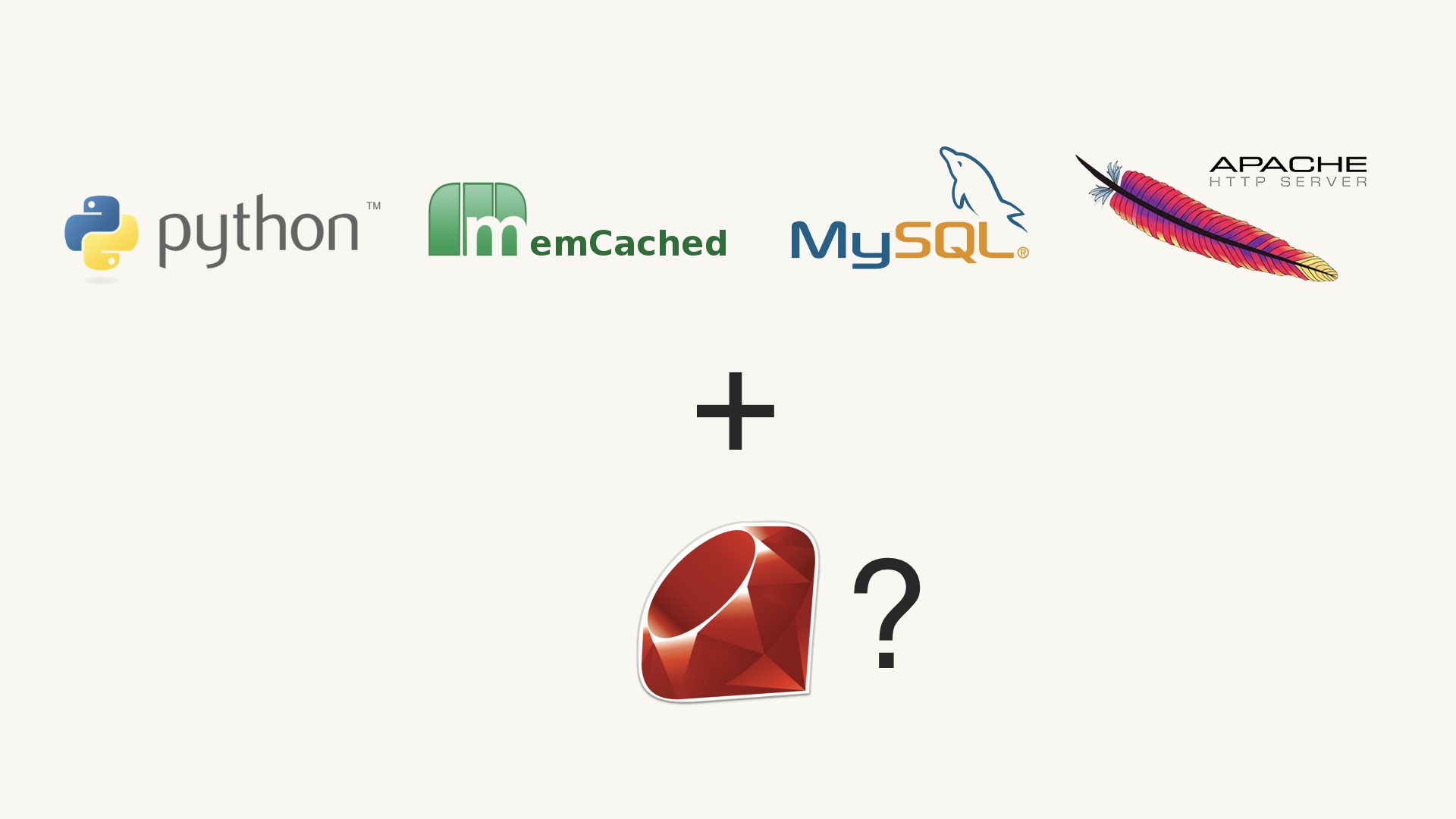
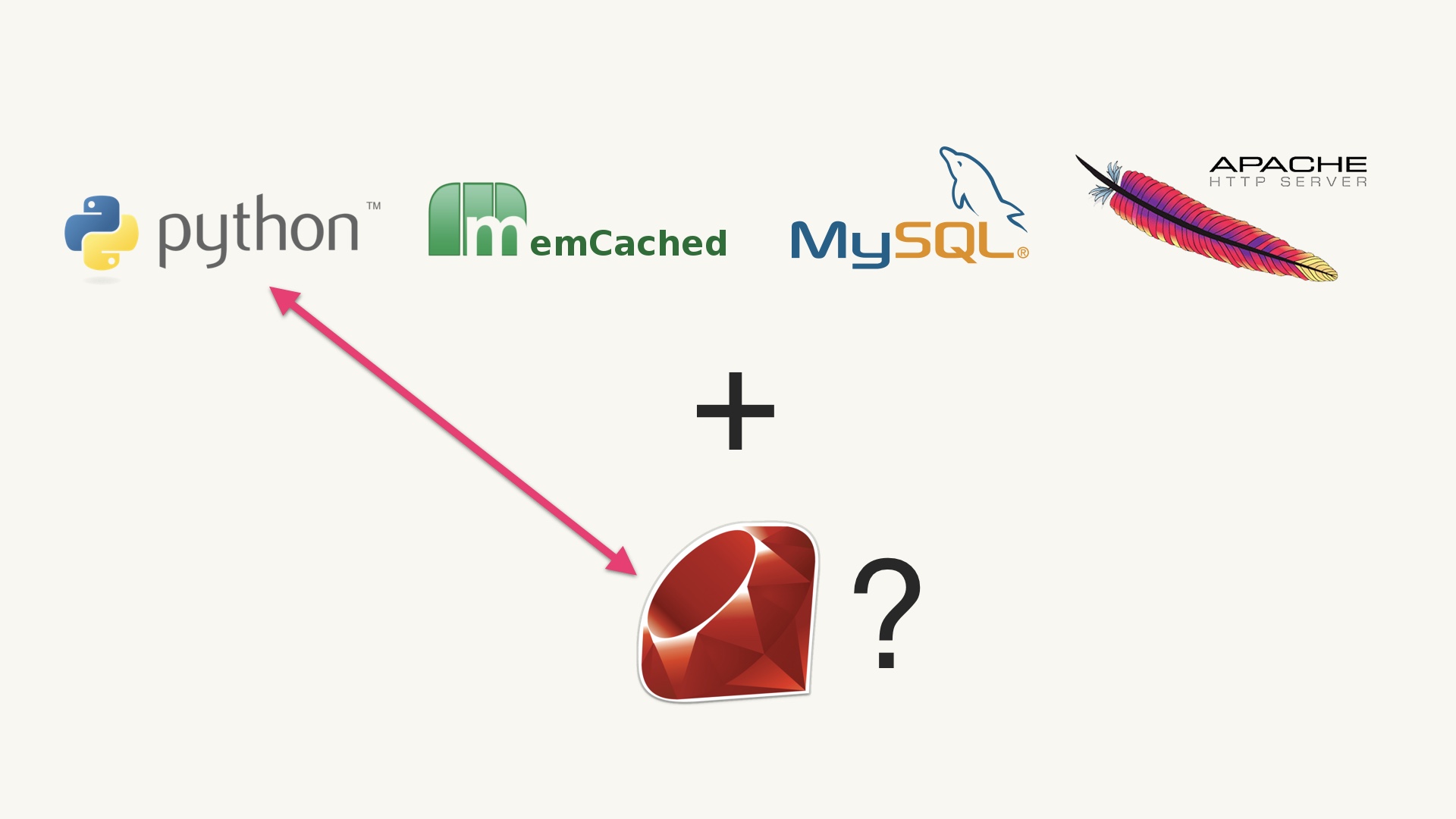
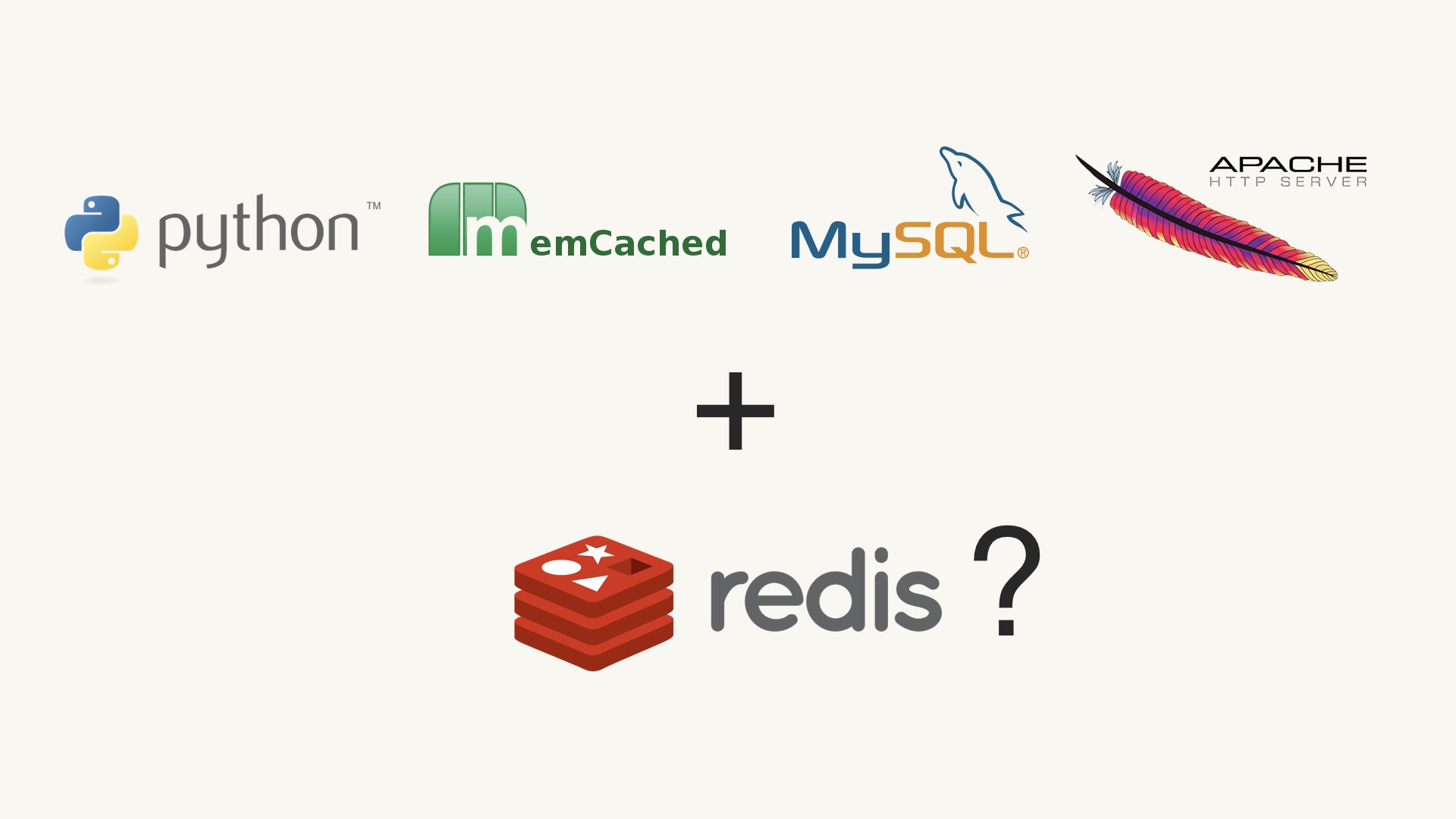
Let’s say that you’re already using this stack. You have Python, Memcached, MySQL, and Apache. # |
|
Let’s say you have a new problem to solve. Do you think it makes sense to add Ruby to your existing stack? # |
|
The intuition of nearly everyone with any seasoning on them at all is “uh, geez, probably not.” We know that the marginal utility of adding ruby isn’t going to outweigh the complexity hit we take by adding it. Python and Ruby are pretty much the same thing. # |
|
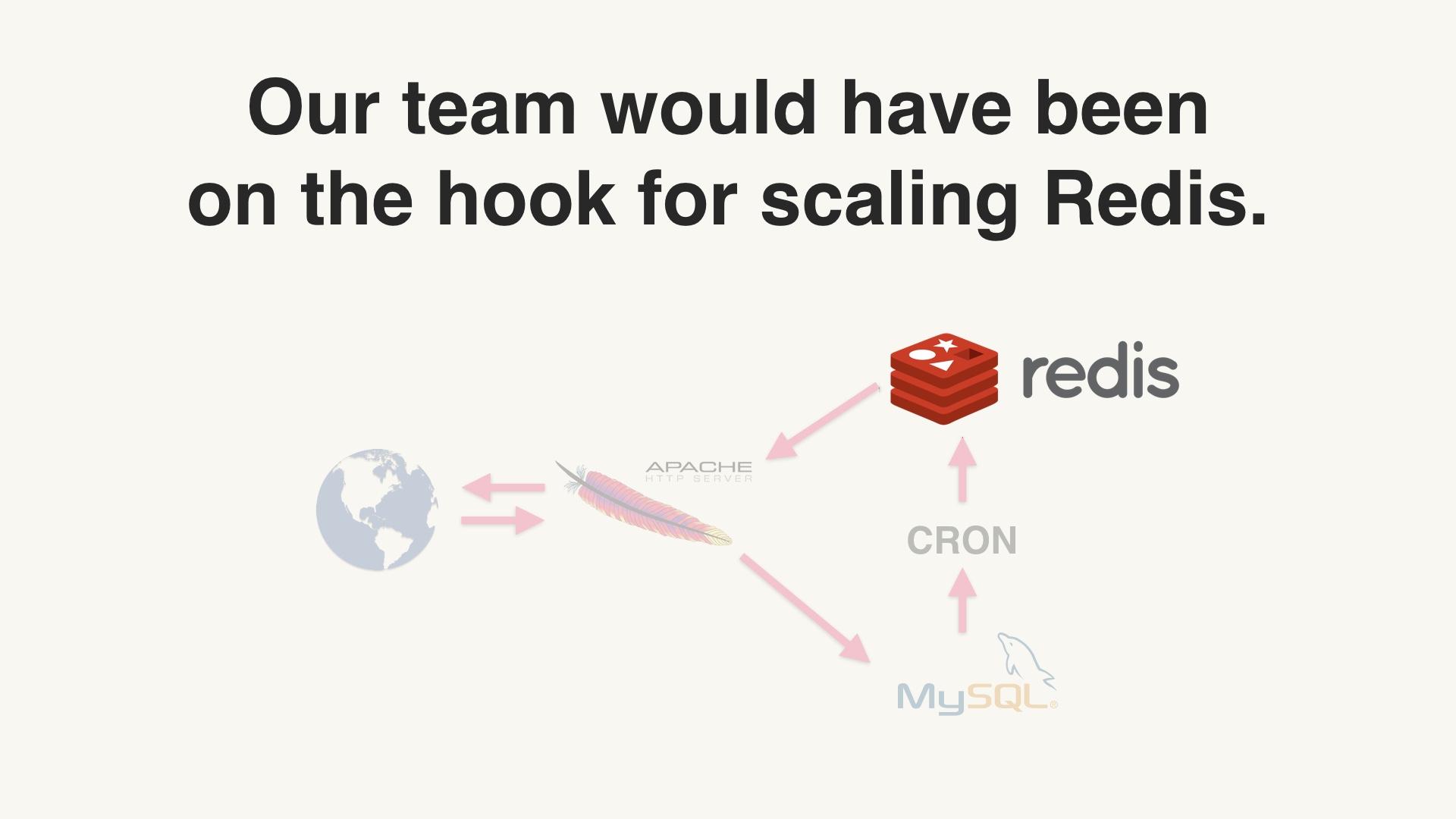
Ok, so how about adding Redis? We already have MySQL and Memcached, but should we add Redis? # |

|
In my experience it is about here where the wheels come off. People lose their shit and start beating their polyglot programmer drums. There’s something about the idea of adding a new database that has people storming the Bastille, saying “you can’t stop us from using the best tool for the job, man.” And when people succumb to this instinct they tell themselves that they’re giving developers freedom. And sure, it is freedom, but it's a very narrow definition of what freedom is. # |

|
What are we actually doing? Let’s dig in. # |

|
This is what we’re implicitly saying when we want to add a piece of semi-redundant technology. We’re saying that the new tech is going to make our work so much easier in the near term that this benefit outweighs the cost of dealing with that technology indefinitely into the future. # |

|
That’s not a very complicated premise. We can try to apply structured thinking to it. # |
|
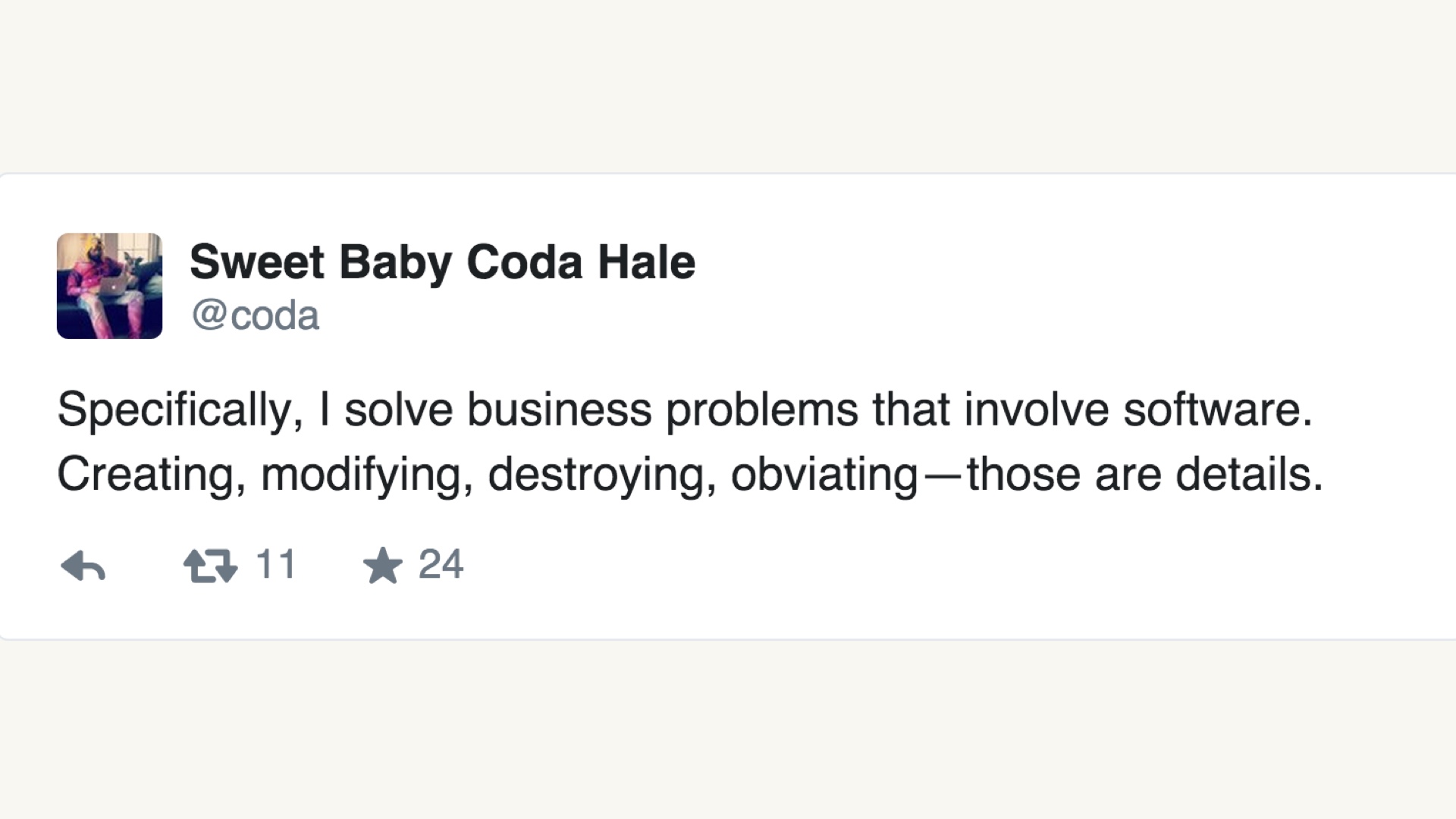
Backing up a bit, your job is what my friend Coda says, here. You’re supposed to be solving business problems with technology. # |
|
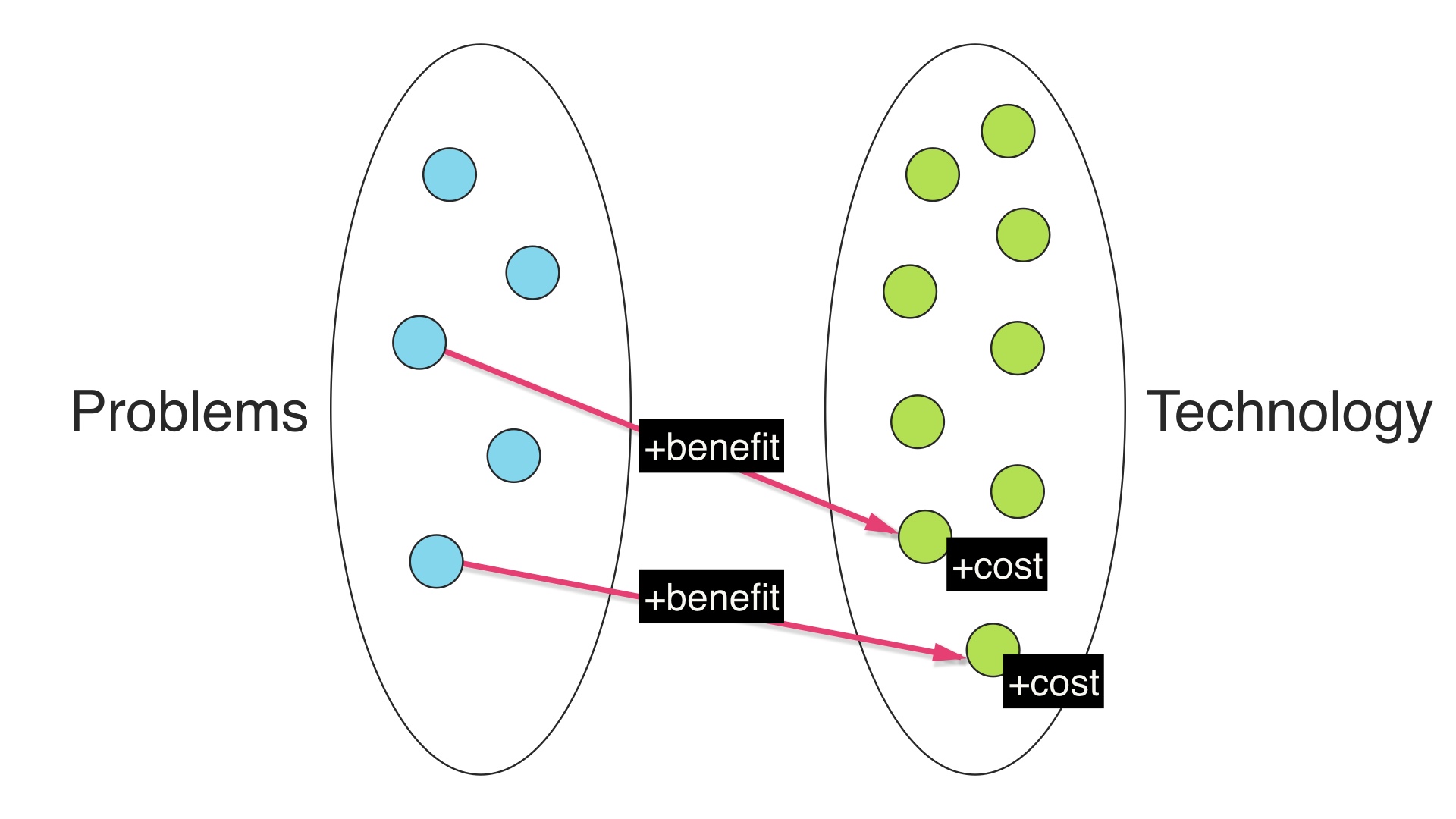
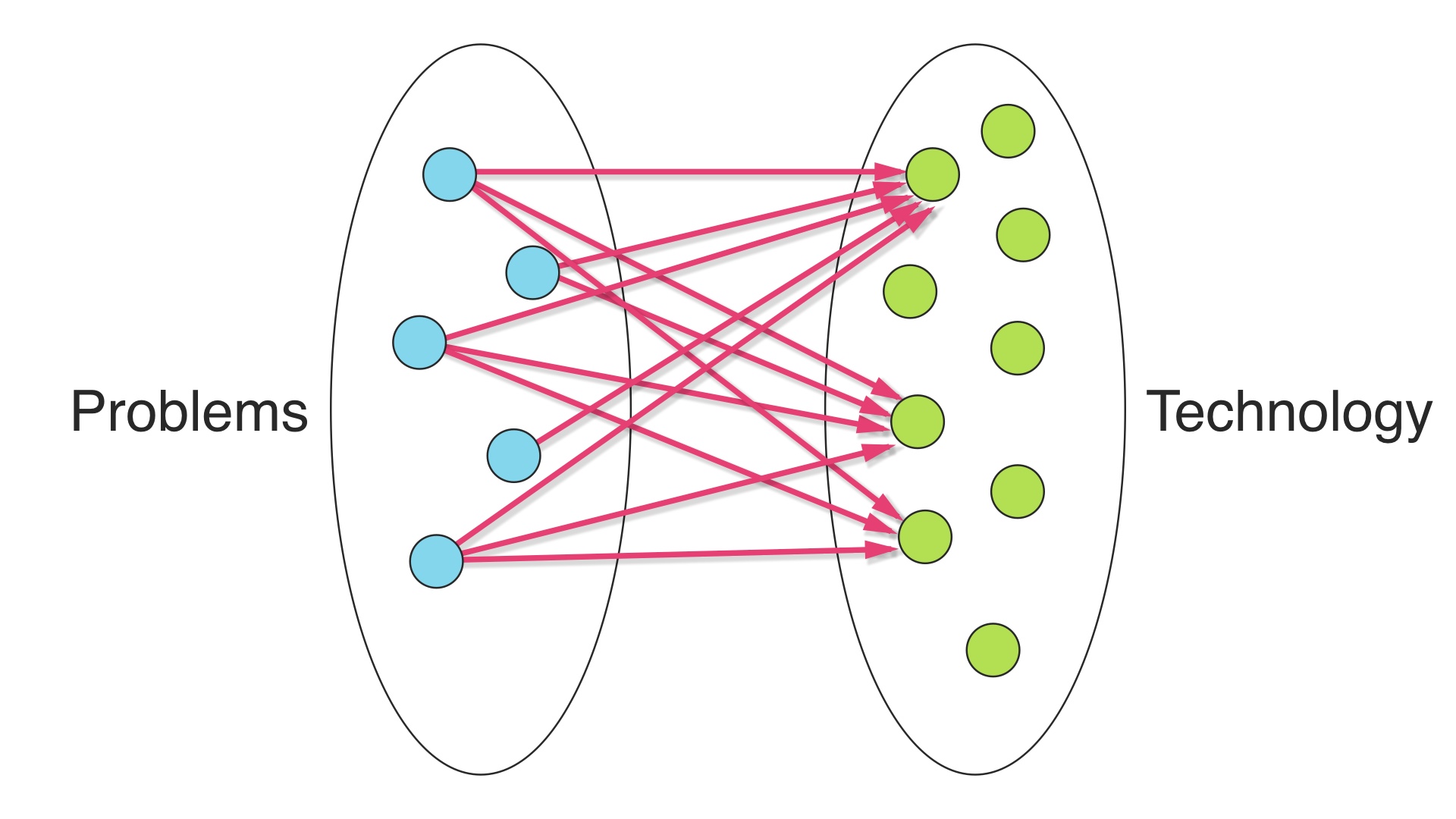
We’re in a field that allegedly has something to do with computer science, so we can pretend to be computer scientists for a minute here and model this situation as a bipartite graph. On the left side we have business problems, and on the right side we have technical solutions. # |
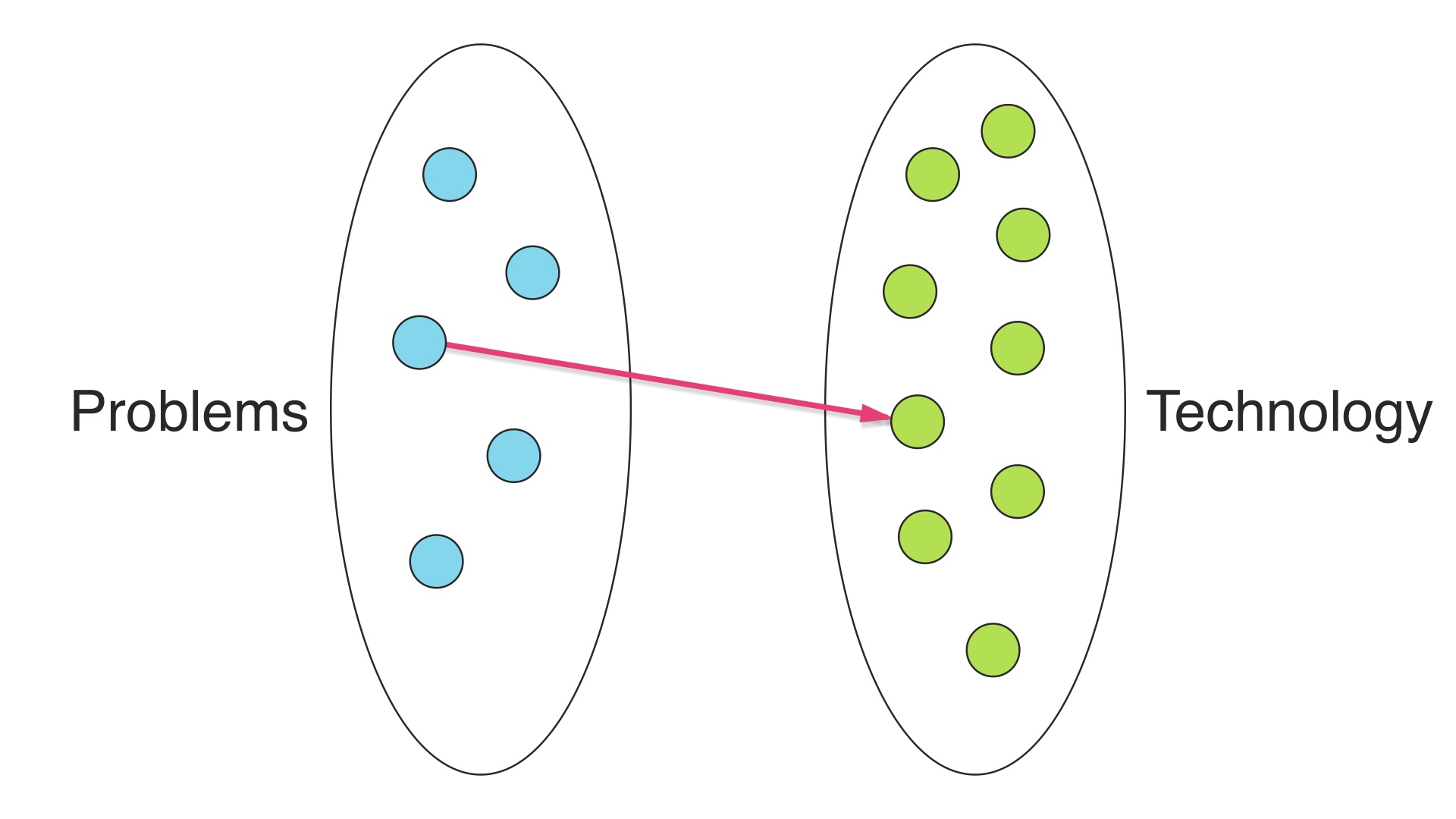
|
We have to try to connect all of the nodes on the left side so that our problems are solved. Adding an edge here is making a technology choice. # |
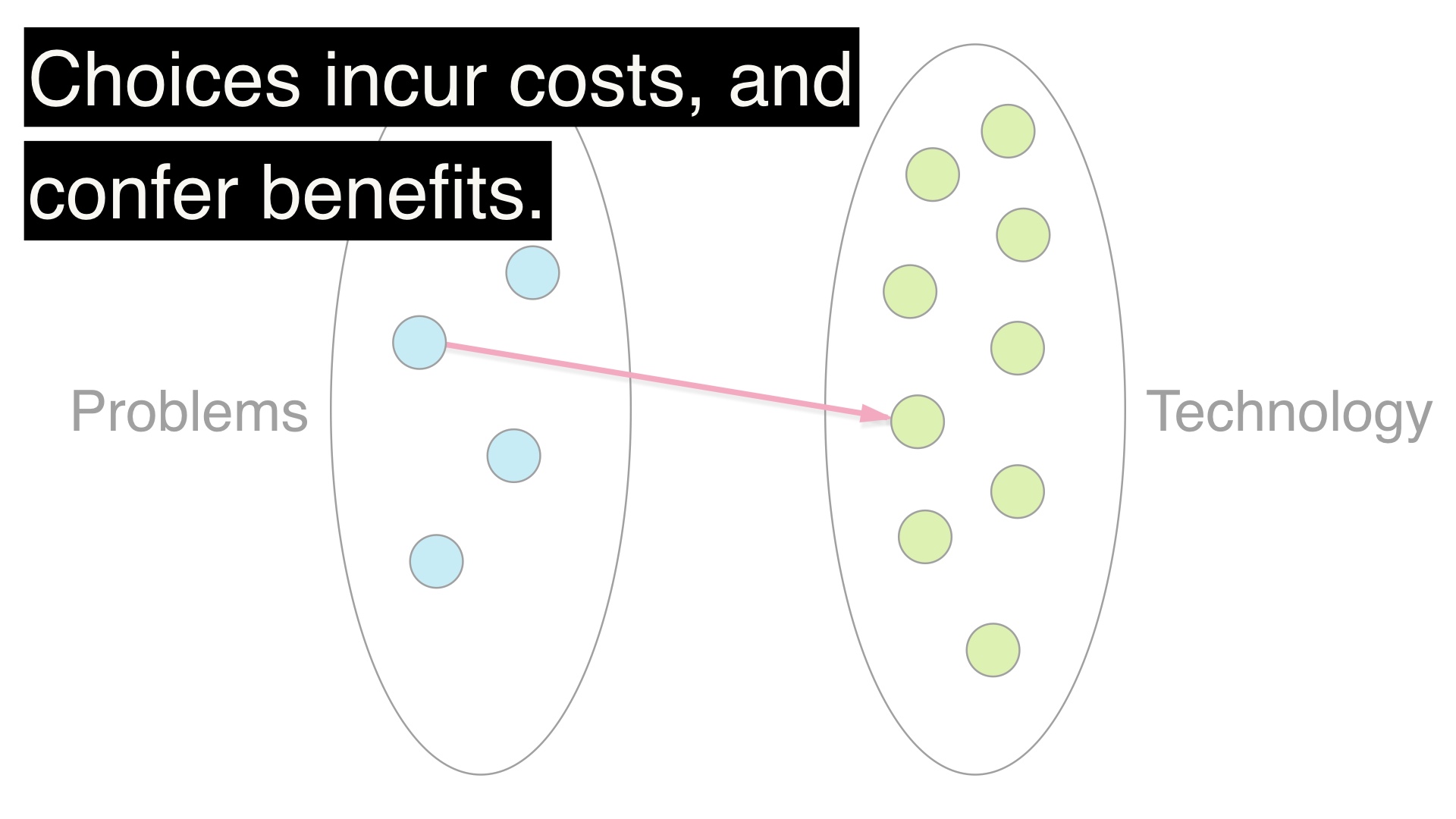
|
Every choice has a maintenance cost, but we also get the benefit of the technology that we choose. We solve the problem, we have capacity for solving additional problems, whatever. # |
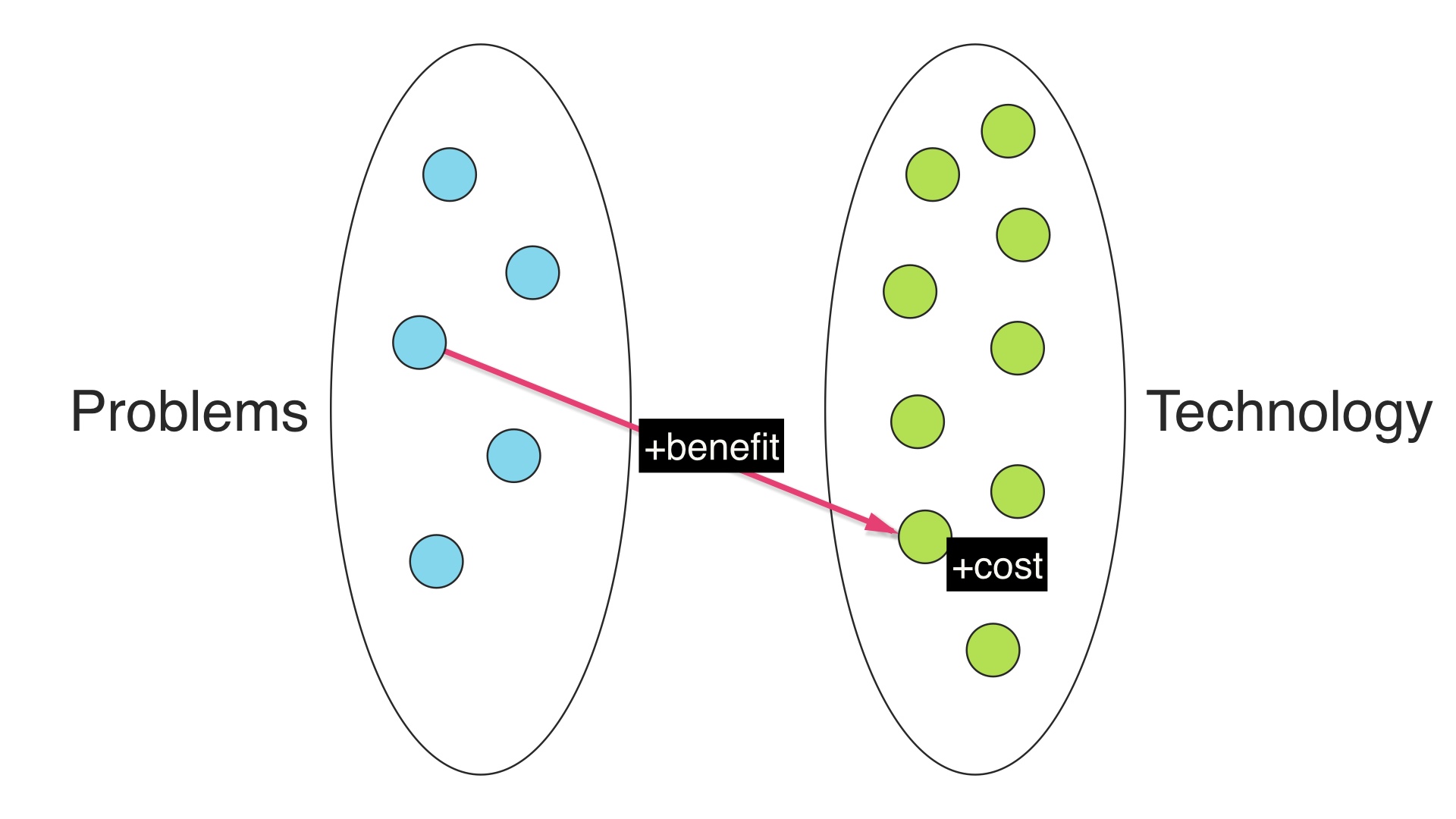
|
So we have a nonzero benefit, and a nonzero cost for every choice. # |
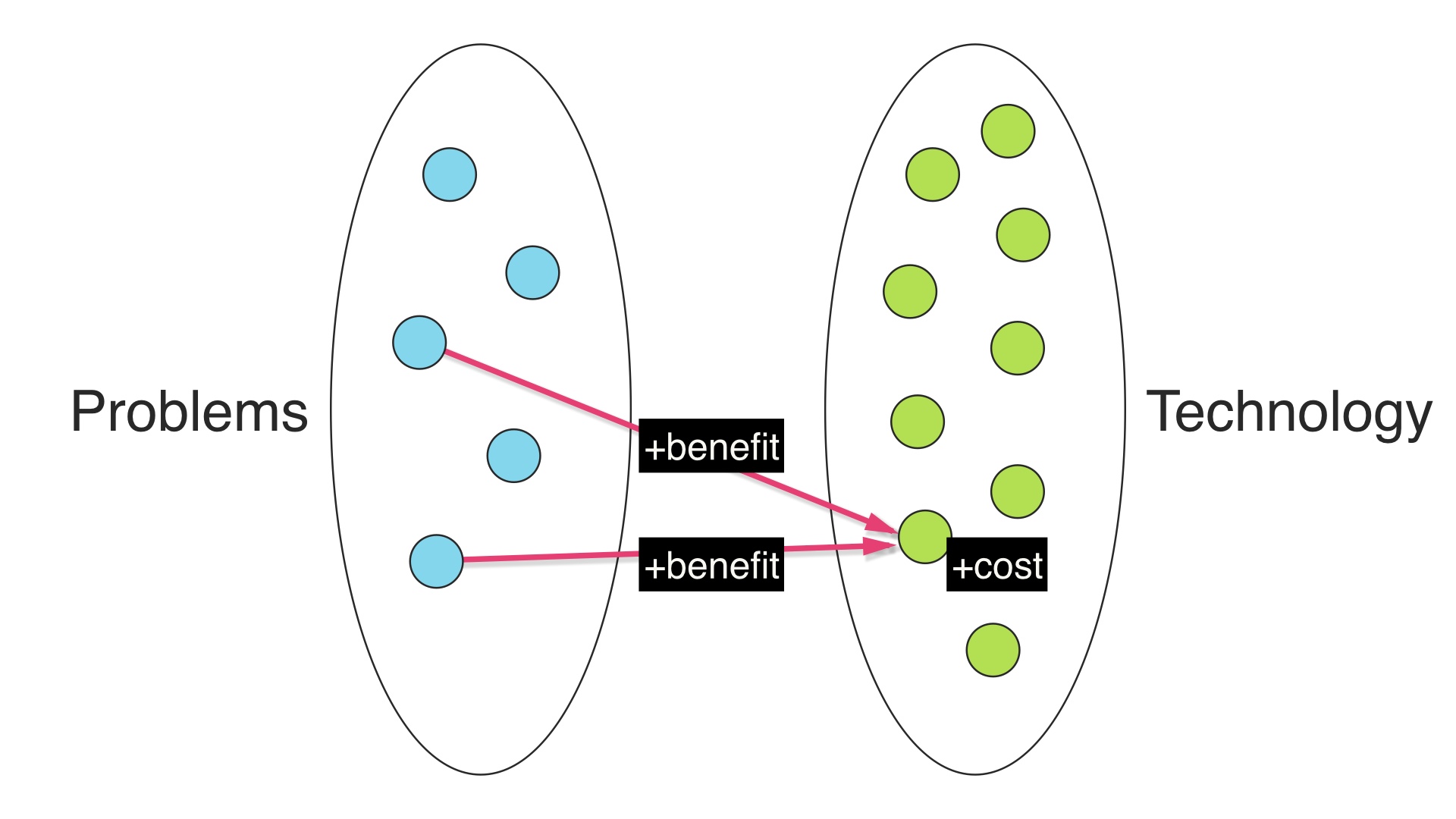
|
When we add more than one edge, we can make a choice. We can use the same technology that we’ve already paid for … # |
|
Or we could pick a different piece of technology. We have to pay for that new tech, too, but maybe we get so much development velocity or endorphins that it’s worth it. # |

|
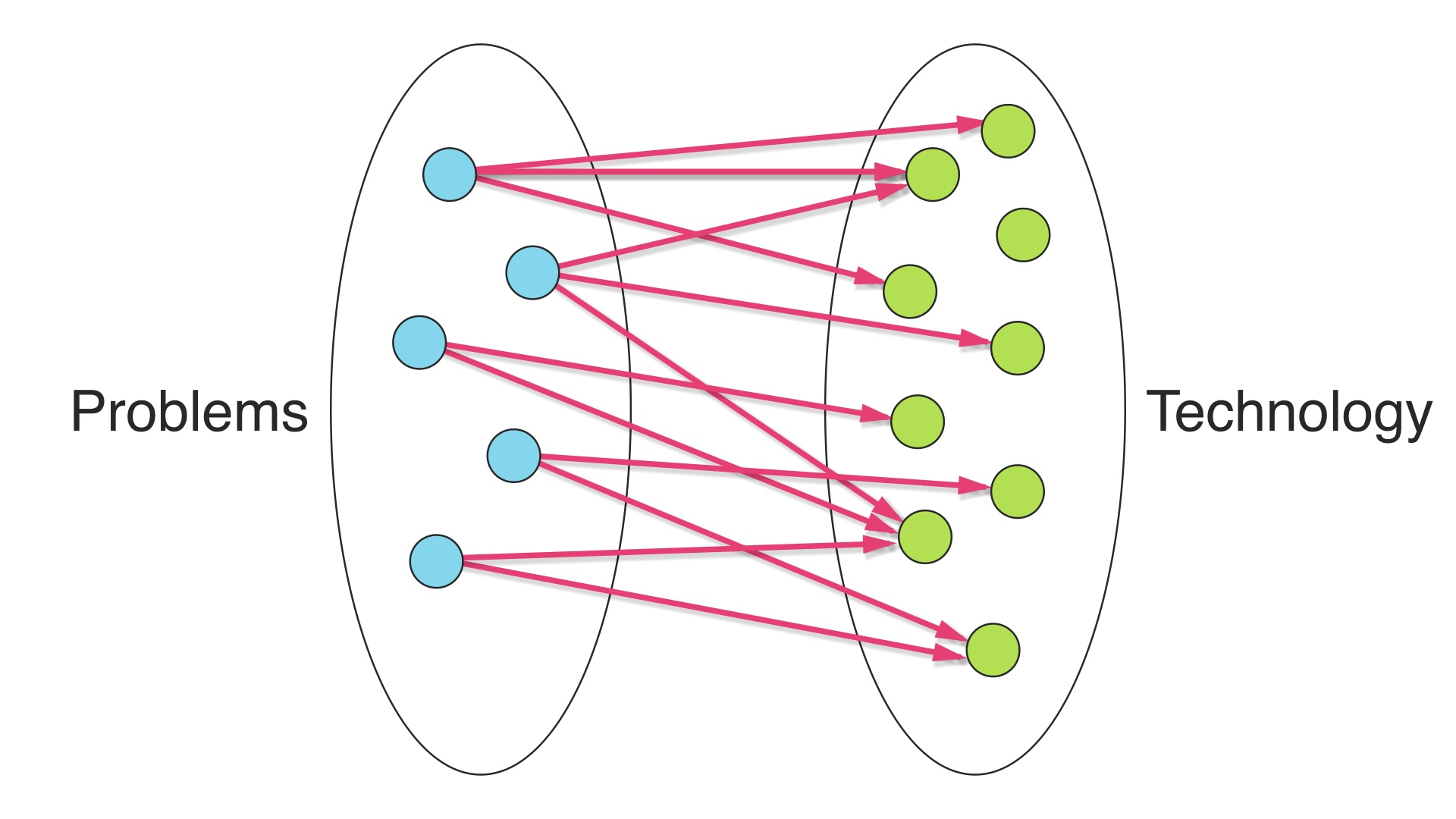
We’re trying to minimize this cost function. The total cost of our operations is all of the maintenance costs we take on from our choices, minus the development velocity and what-have-yous that we get from every choice. # |

|
The way we behave really depends on what you believe about which term dominates this equation in the real world. If technology is really expensive to operate, the costs dominate. If technology really makes a huge difference in how easy your job is, the benefits dominate. # |
|
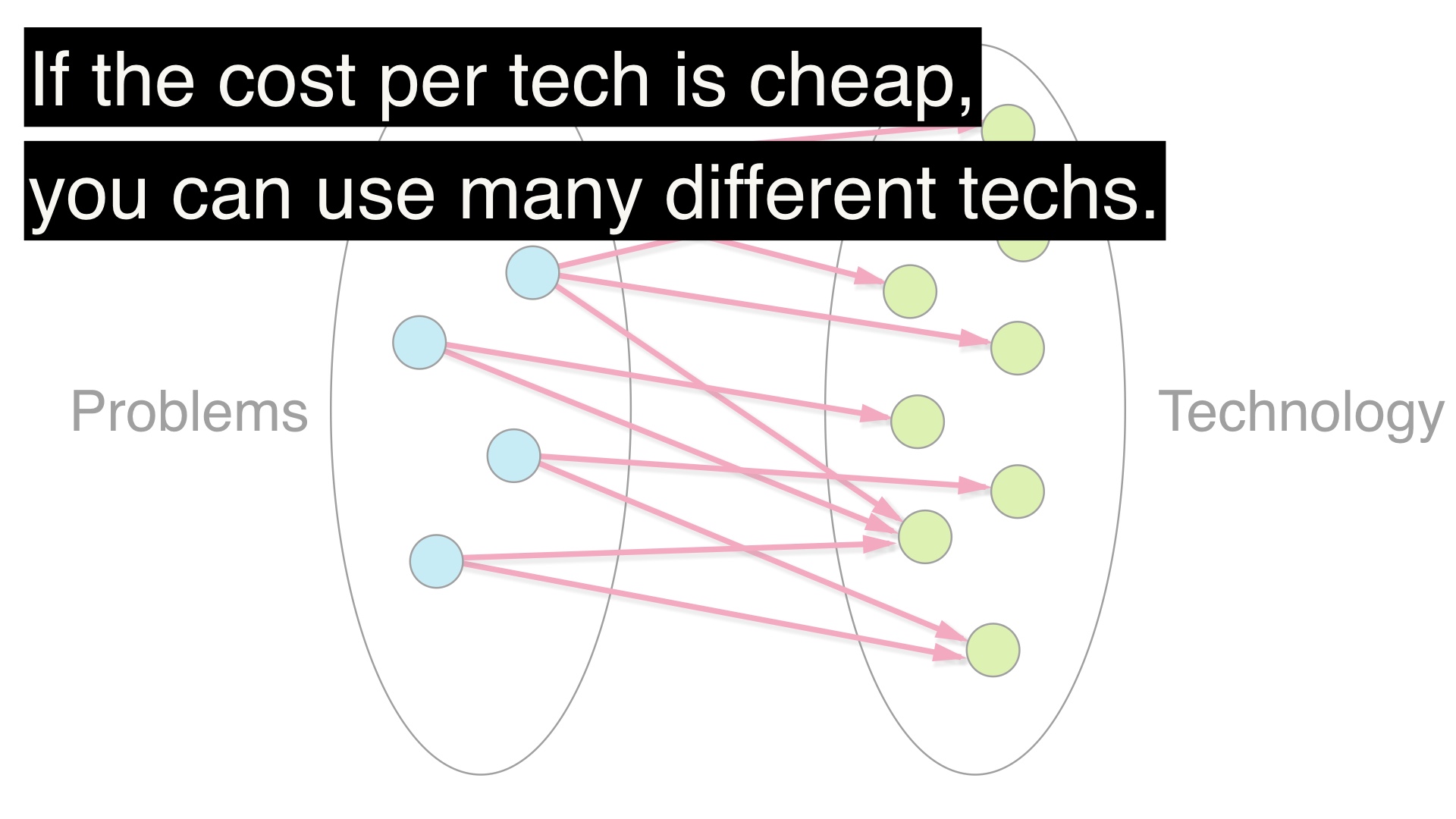
So, depending, you might decide to make an allocation like this. Here we’ve picked many different technologies to use to solve all of our problems. # |
|
And that makes complete sense if each additional technology choice is cheap. # |
|
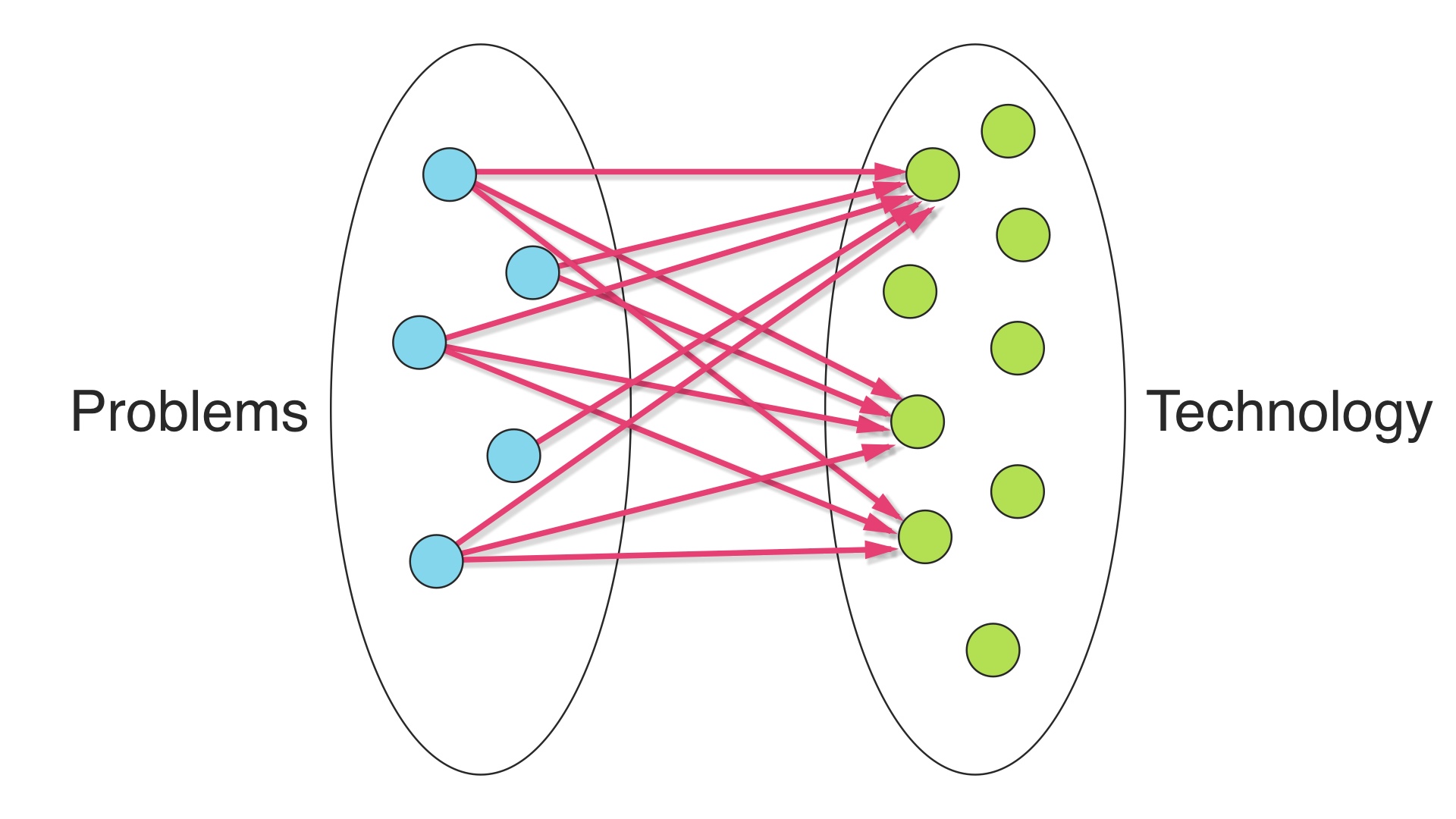
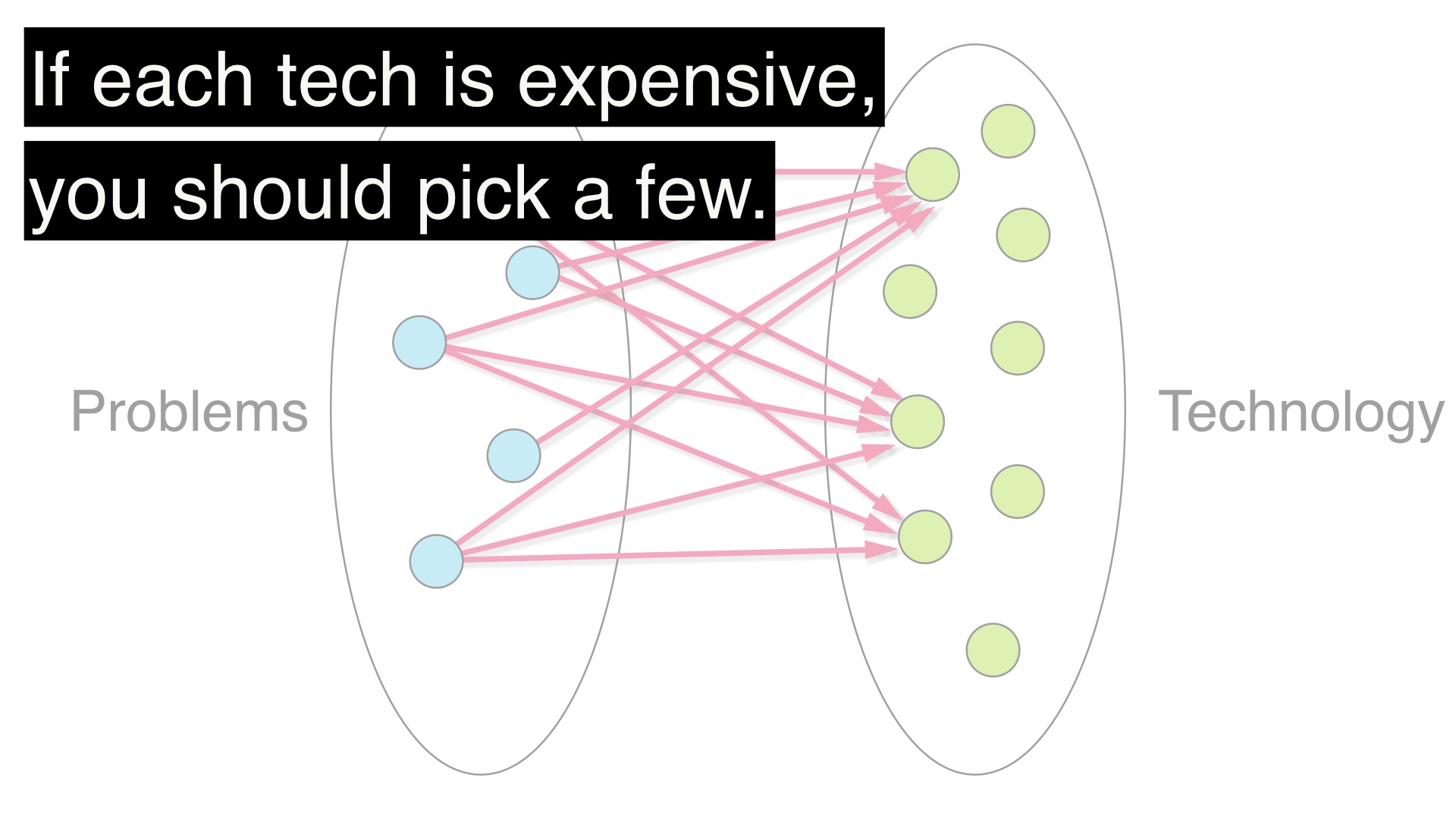
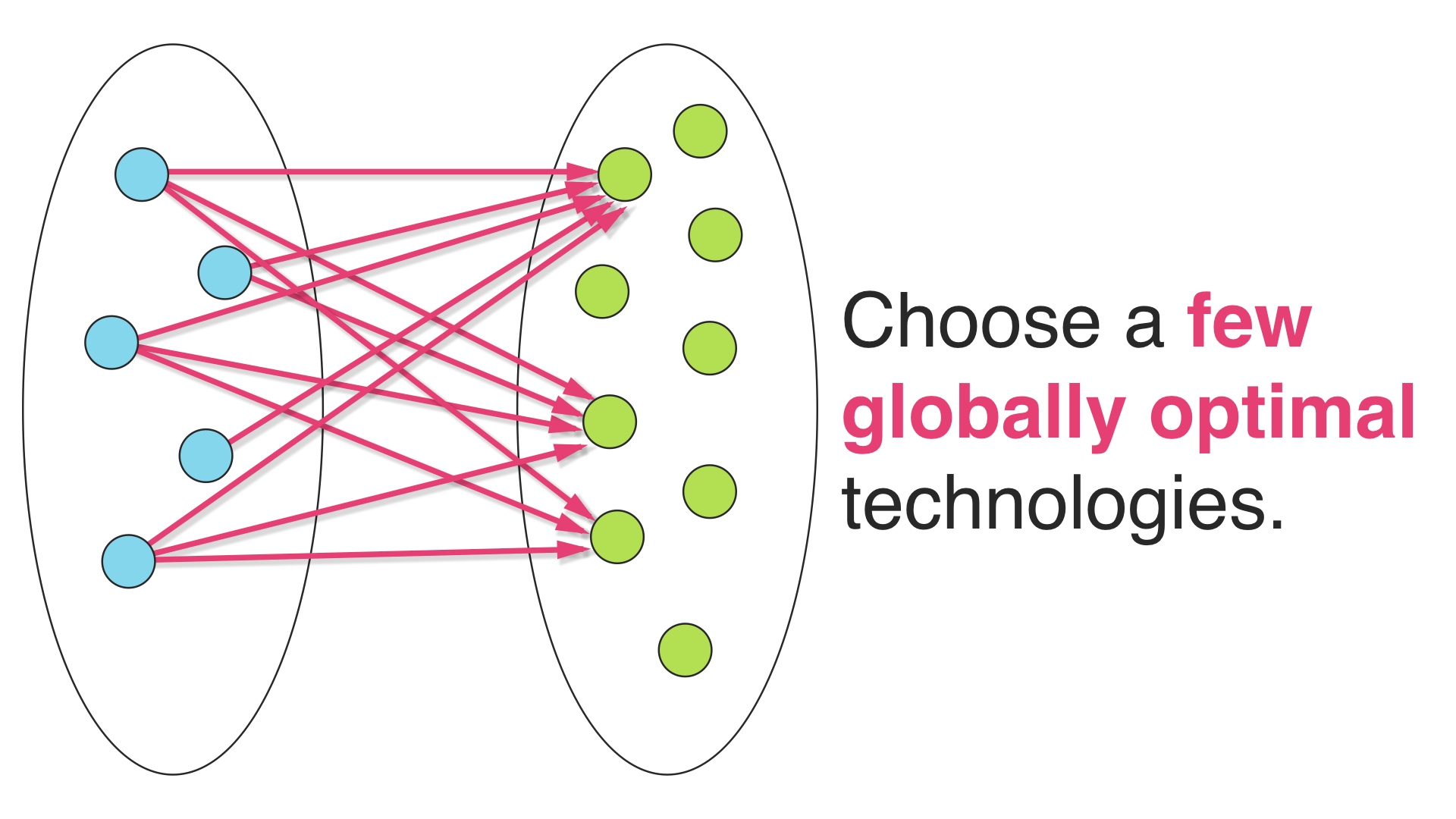
This is an alternative strategy. Here we’ve chosen just a few technologies that cover our domain, and solved all of our problems with them. # |
|
And that’s what we should do if we think that each technology we add comes with a lot of baggage. # |

|
Here in reality, new technology choices come with a great deal of baggage. # |

|
This is reality. Costs to operate a technology in perpetuity tend to outstrip the convenience you get by using something different. # |
|
So this tends to be the right way to arrange things. We should generally pick the smallest set of tech that covers our problem domain, and lets us get the job done. # |

|
That’s the case because operating a piece of technology at a professional level turns out to be really hard. It’s easy to get started with a lot of technology, but harder to do a really good job with it. # |

|
This is why. Adding the technology is easy, living with it is hard. These are all the things you have to worry about. I could brew install a new database right here right now while giving this talk, and start writing some data to it. God help me I could, don’t make me do it. But it’s another matter entirely to run that thing in production at a professional level. # |

|
So polyglot persistence is not the kind of freedom we are looking for, and honestly I wish Martin Fowler would just take the damn bliki about it down already. If you’re giving individual teams (or gods help you, individuals) free reign to make local decisions about infrastructure, you’re hurting yourself globally. It’s freedom, sure. You’re handing developers a ball of chain and padlocks and telling them to feel free to bind themselves to the operational toil that will be with them until the sweet release of grim death. # |

|
It gets worse. There’s more to this than just avoiding duplication of effort, and an excess of operational overhead. By embracing polyglot persistence, you’re also discarding real, positive benefits that only arise when everyone’s using a shared platform. # |
|
A good example of this from my past is Etsy’s activity feeds. Twitter is/was an activity feed, Facebook’s newsfeed is one too. Etsy spent many years dabbling in VC funding and coincidentally I guess also wanted a feed just like theirs. I built this with a small team back in 2010. It was pretty fun. # |
|
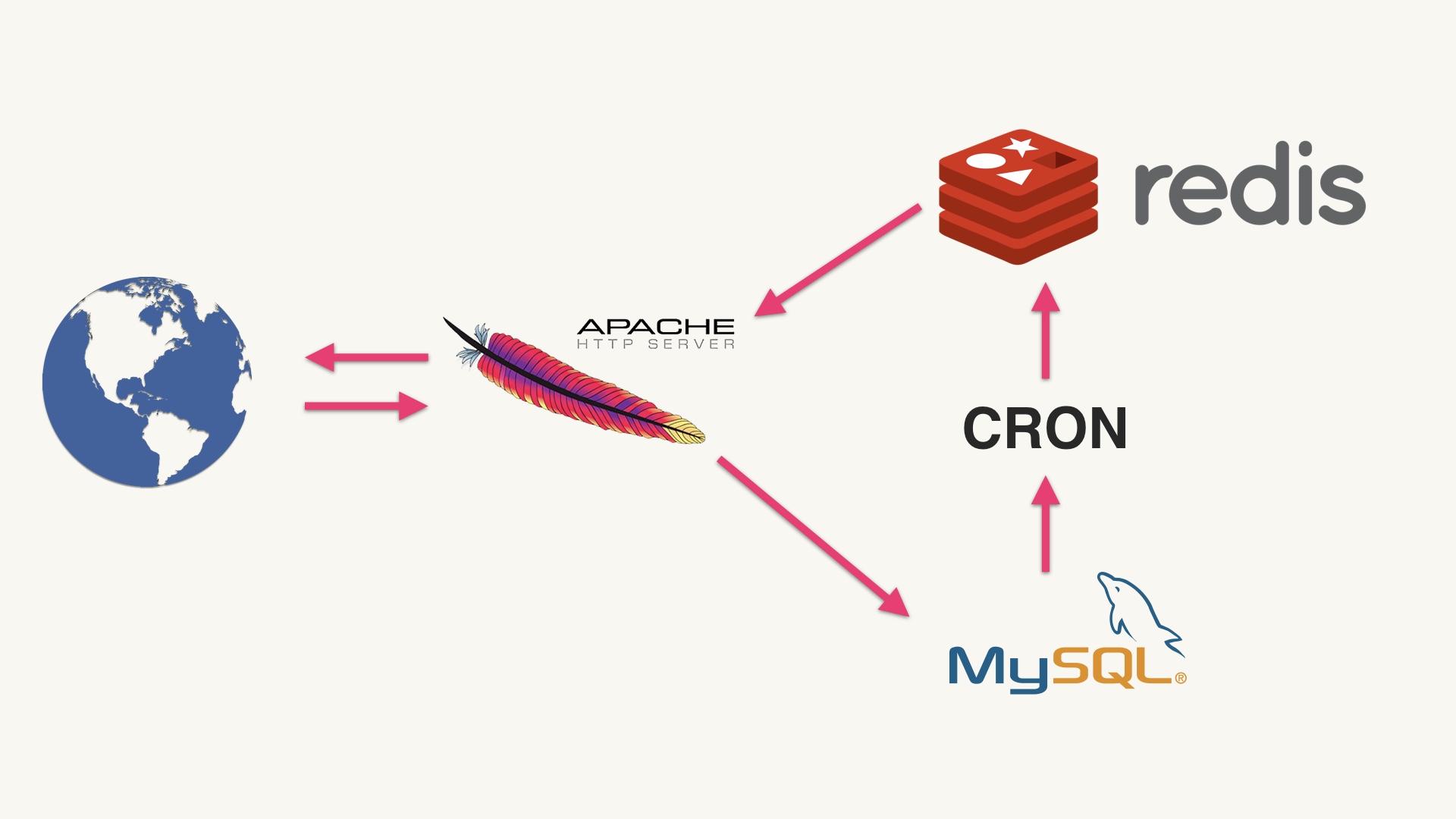
Here’s a totally reasonable way to build activity feeds, if that’s all you’re trying to do. You get events from the outside world, then you write them to a database. Then an offline process comes along and aggregates those, sprinkles some machine learning on things, and stuffs a materialized newsfeed into a thing like Redis for serving frontend traffic. This would totally work great. # |
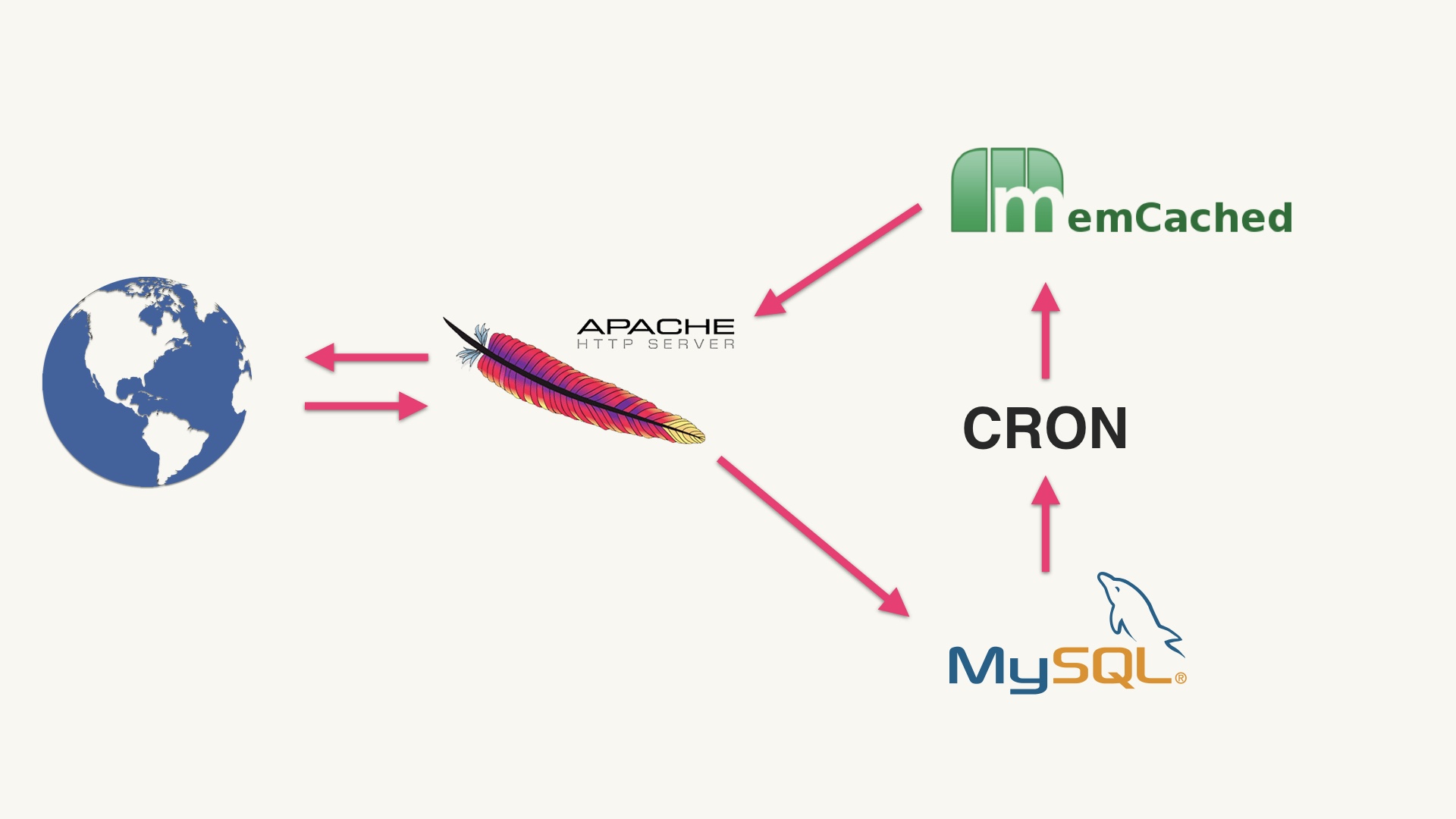
|
But when we set out to build activity feeds, we didn’t have Redis. We did have Memcached. They’re sort of similar in the sense that you can shove a blob in them, and get it back out with a similar API. But they have very different guarantees. The most relevant difference to us here is that Redis is persistent, and Memcached is ephemeral. # |
|
What that means is that if you want to build an activity feed with Memcached, you have to do a bunch of extra work. You have to cope with the possibility that Memcached has gotten rid of your data at the moment you want it. That creates a ton more work when it comes to writing the code to deliver the feature. But we weighed that against the persistent cost of operating a new kind of database, and decided that we’d bite the bullet and build the feature on Memcached. # |

|
Then we walked away. We didn’t do anything related to activity feeds for years after that. We barely even thought about it. # |

|
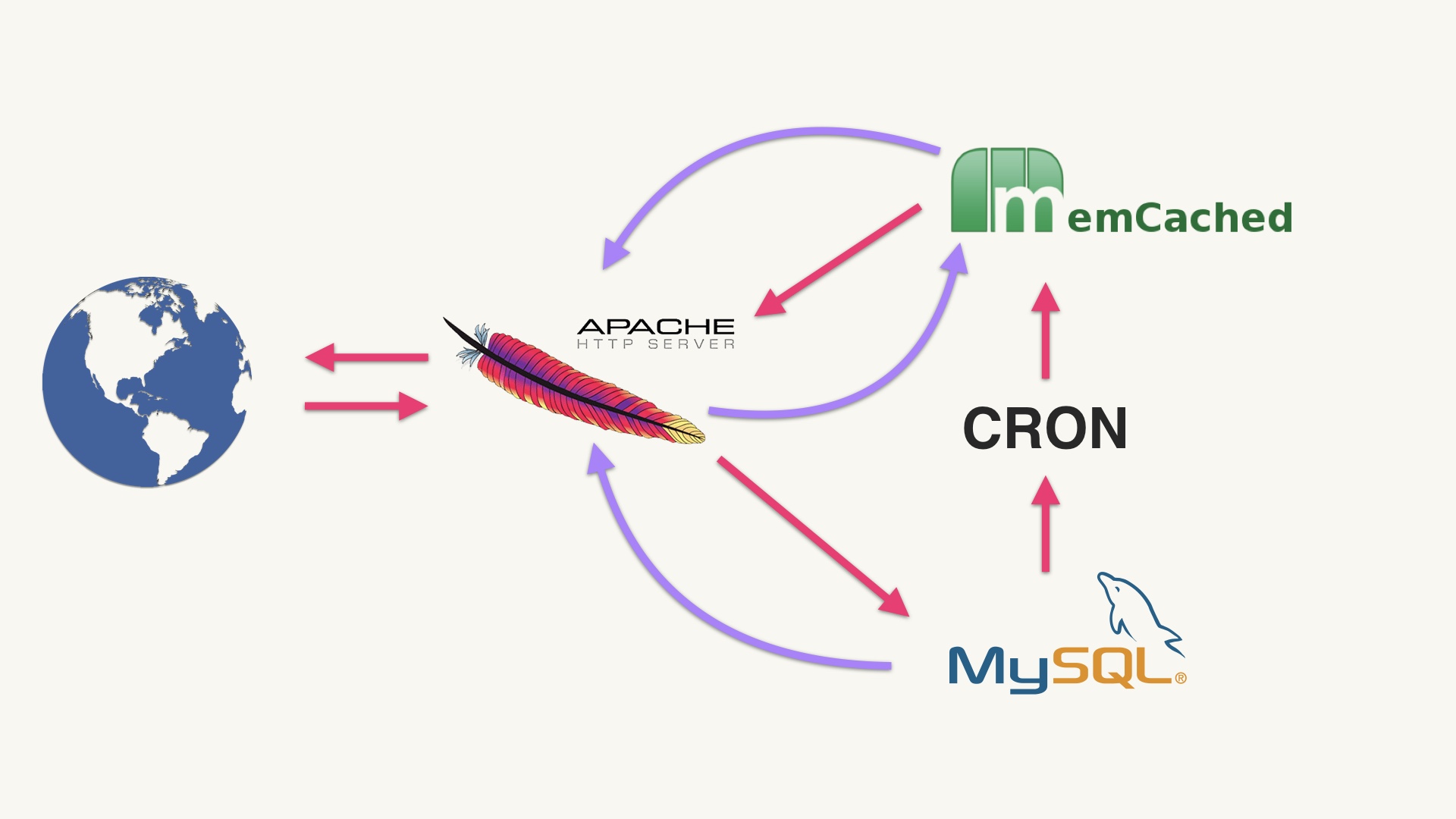
Then one day I said, “hey, I wonder how activity feeds is doing.” And I looked at it and was surprised to discover that in the time since we’d launched it, the usage had increased by a factor of 20. And as far as I could tell it was totally fine. The fact that 2,000% more people could be using activity feeds and we didn’t even have any idea that it was happening is certainly the greatest purely technical achievement of my career. # |
|
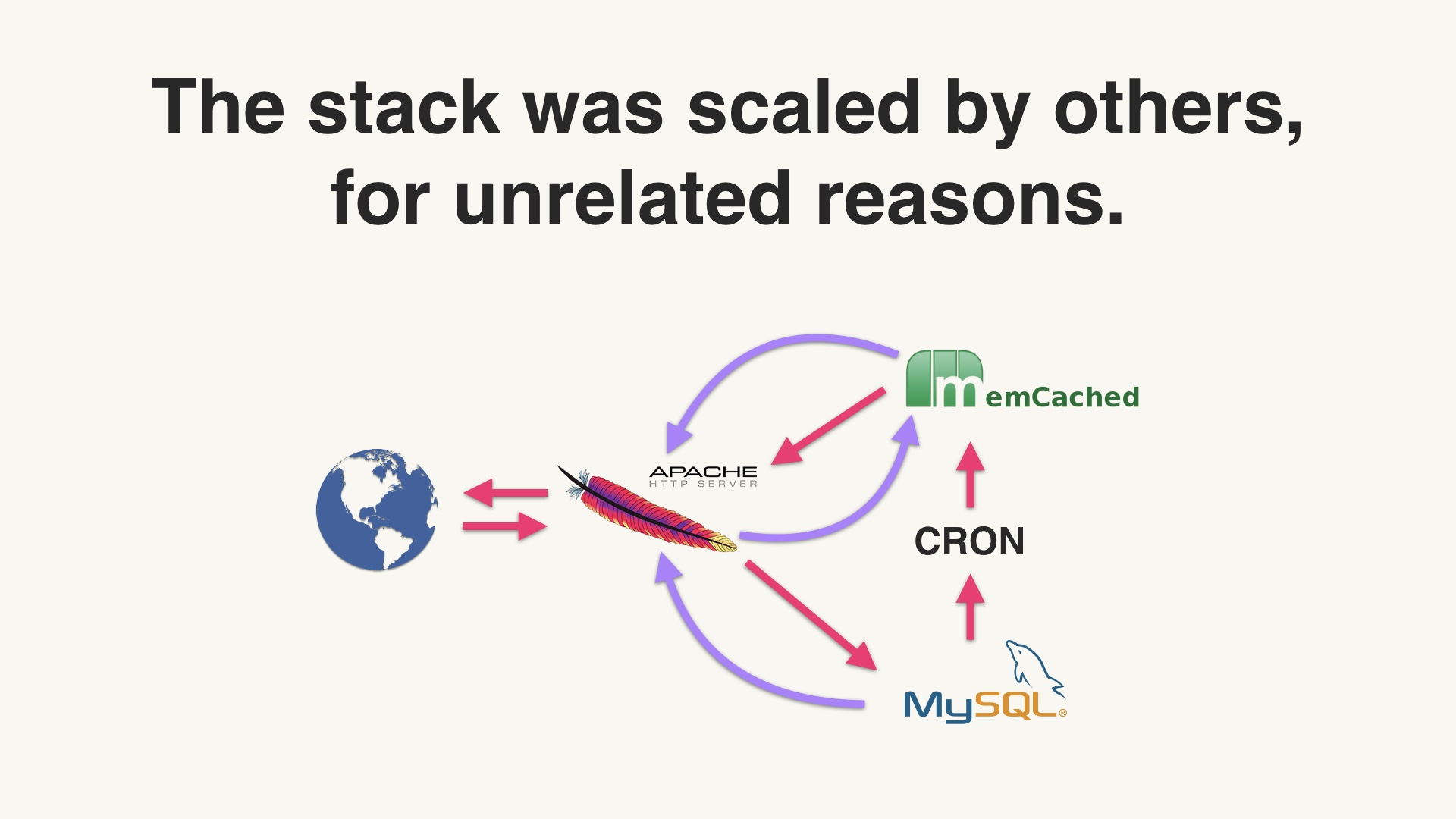
The reason it was possible was because we used the shared stack. There were people around whose job involved noticing that we needed more MySQL’s or cron boxes or whatever. And there were other people who had to go to the datacenter and plug in new machines. But they were doing that horizontal scaling because the site was growing holistically. Nobody doing this had any awareness of our lone feature. # |
|
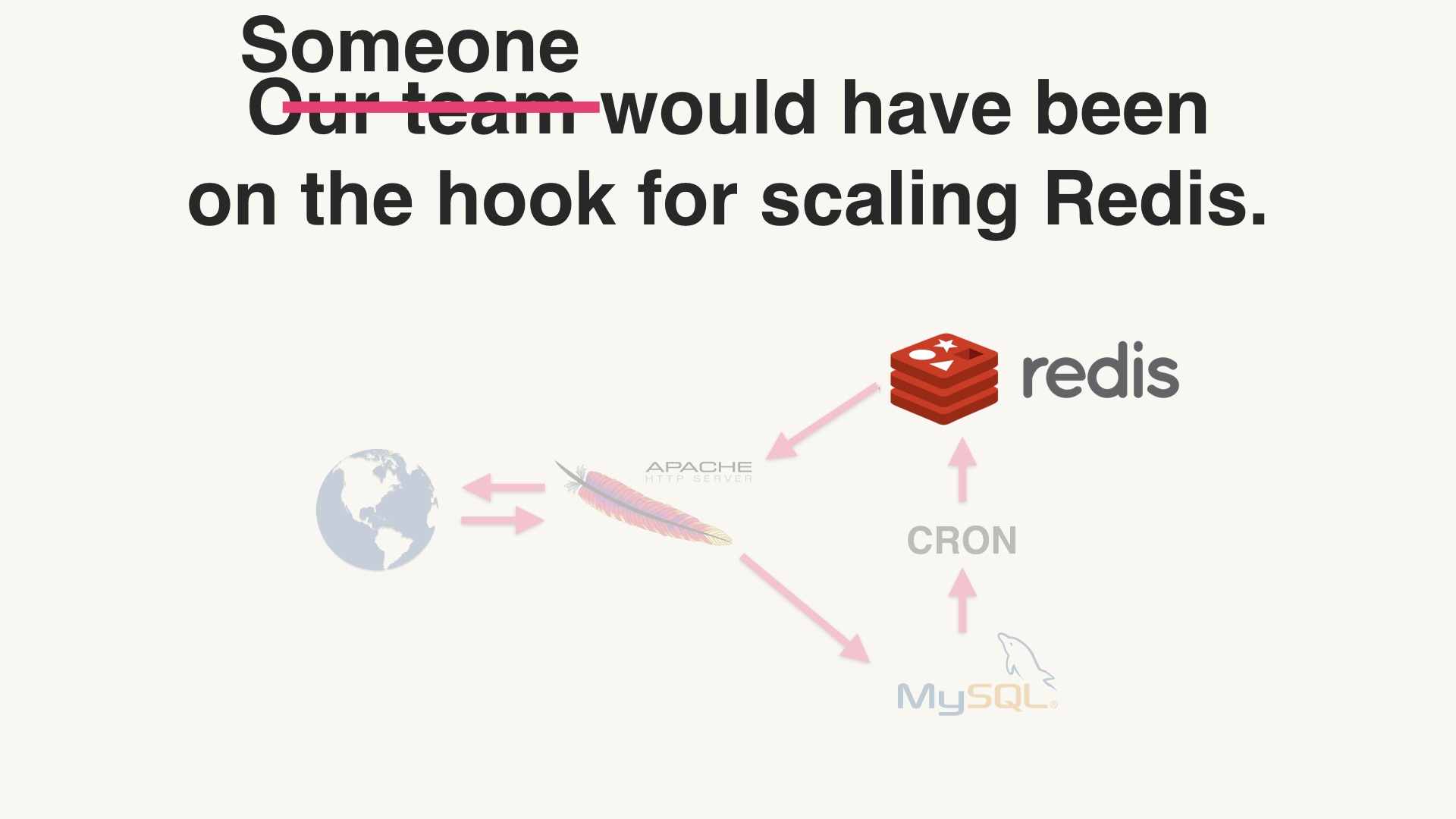
If we’d deployed Redis just for activity feeds, you can be sure that Redis would have become distressed at some point as the feature scaled up 20 times. And we would have had to go back and work on Redis just to keep activity feeds working. # |
|
Or more likely, someone else would have had to do it. Our team didn’t exist at all a year later, we were all working on different things. Something I have noticed is that people like cleaning up my messes even less than they like cleaning up their own messes. So this would have gotten awkward and terrible for everyone. # |

|
So I’m making a case here that you should tend to prefer mature things, and you should try not to use too many things. But it’s not an absolute principle. Obviously sometimes it does make sense to add new technology to your stack. And it can even make sense to use a weird new thing. # |

|
So I wanted to talk a bit about how you might go about doing that. # |

|
The long and short of it is that you have to talk to each other. Technology has global effects on your company, it isn’t something that should be left to individual engineers. You have to figure out a way to make adding technology a conversation. This might be underwhelming if you were expecting a big insightful secret here, but trust me, this is beyond many technology organizations. # |

|
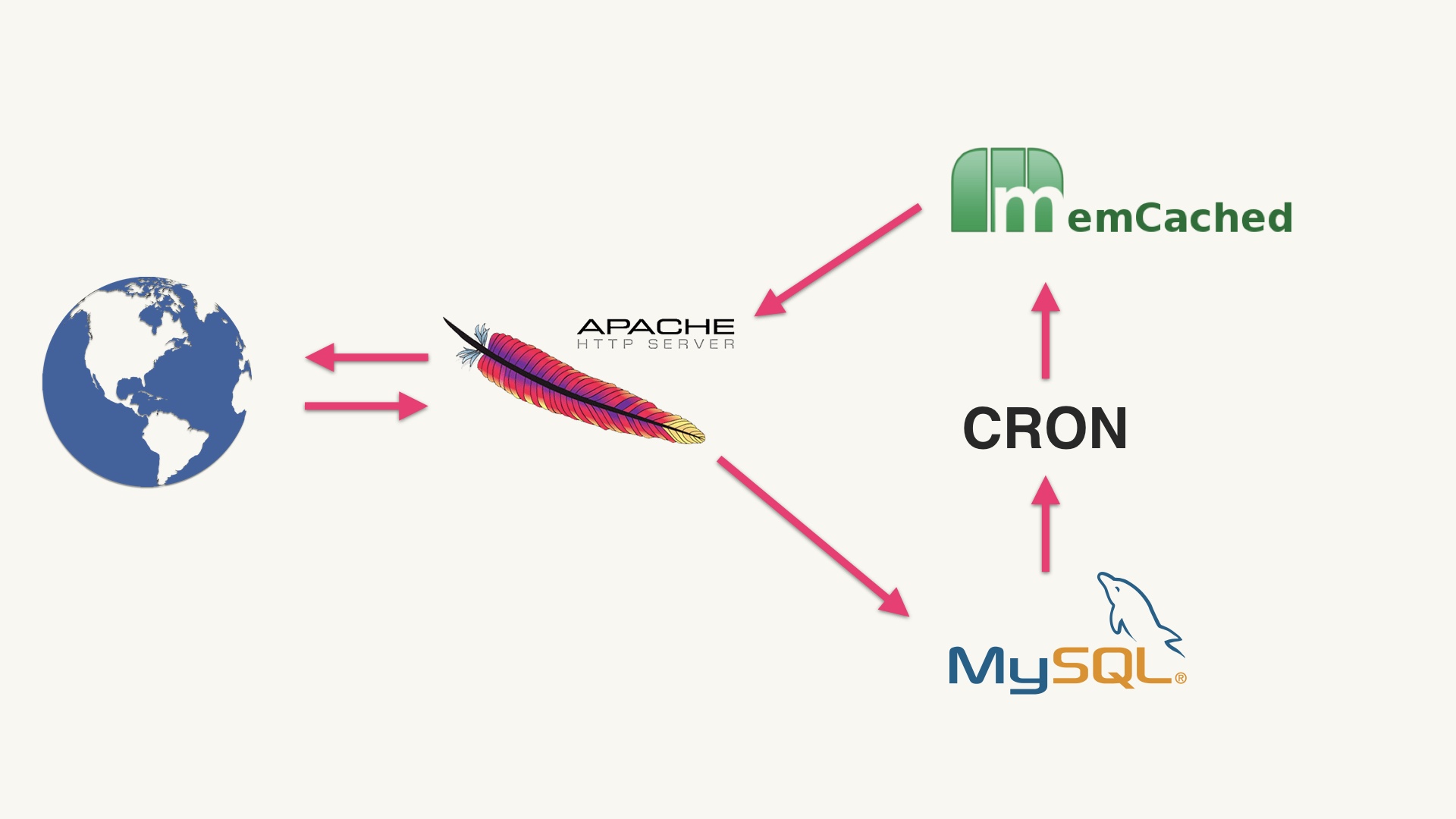
Let’s say you’ve succeeded in gatekeeping new pieces of technology with a conversation. An excellent first question in such a conversation is: “how would we solve the problem at hand without adding anything new?” # |

|
This is a great question to ask because it immediately identifies the situation in which the problem is that we’d like to use a new piece of technology. “Um the problem is that we don’t use Cassandra but maybe we could.” That kind of thing. If you identify this situation, that’s great, because you can immediately stop talking about it. # |
|
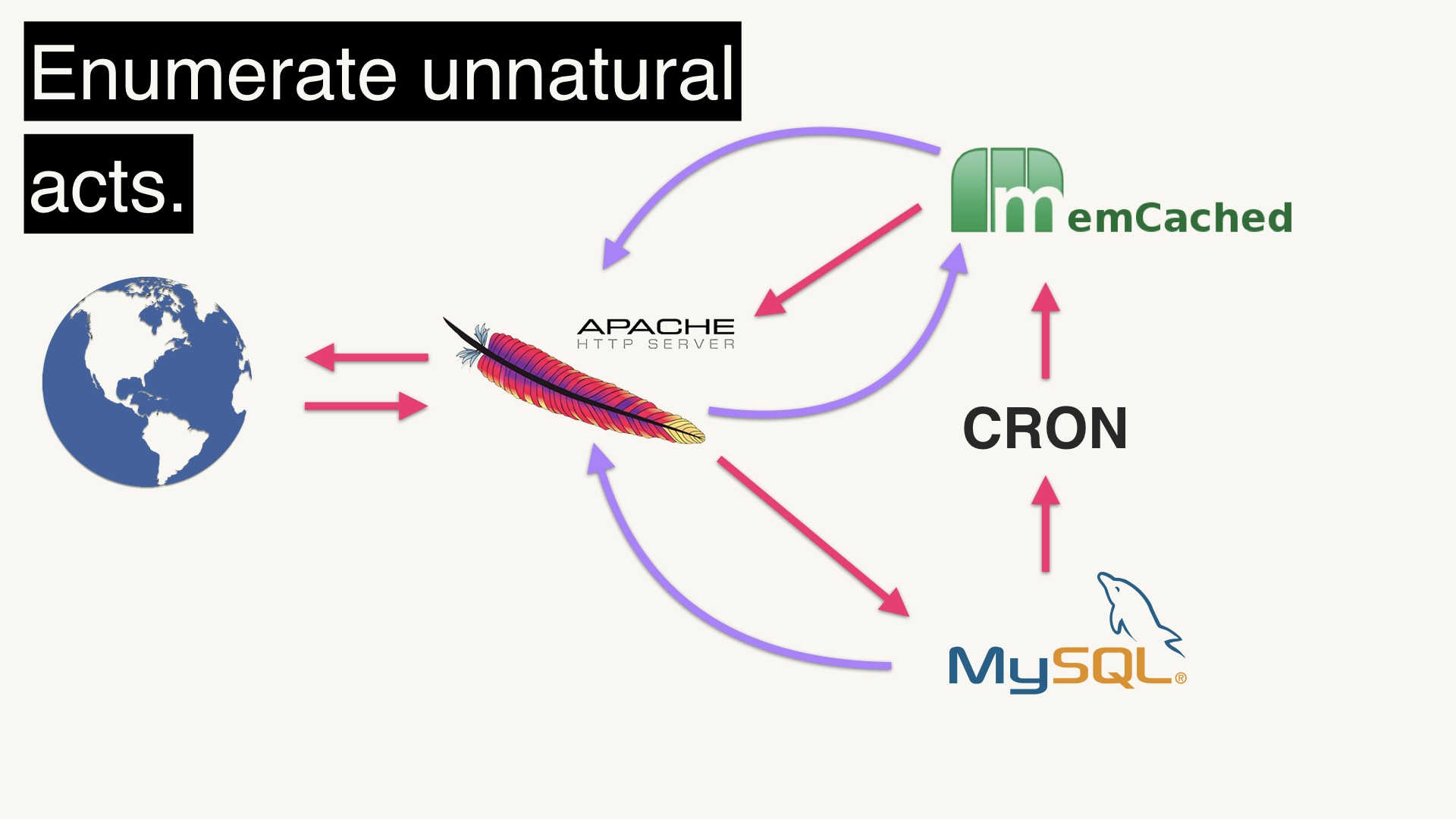
But anyway, assuming that you have a real problem, the answer is rarely that you can’t do it. If you have a functioning service of any complexity in production already, and you think you can’t accomplish a specific new feature with what you’ve already have, you’re probably just not thinking hard enough. You may need to resort to unnatural acts, but you can get pretty far with a minimal stack. # |
|
It’s really worthwhile to actually write down what all of the awkward things you’d have to do are. A lot of the time when you do this, you realize that the situation isn’t really that bad. Or it may be bad, but not as bad as the task of operationalizing a new thing. But it can go the other way, too. You can list all of the unnatural acts and conclude that adding a new thing will be worth it. # |

|
And if you decide to try out a new piece of technology, you should figure out low-risk ways to get started. Your tactic should not be to rewrite your entire application with it in one step. You should be proving the technology in production with minimal risk, and then gradually gaining confidence in it. # |

|
If you’re adding a redundant piece of technology, your goal is to replace something with it. Your goal shouldn’t be to operate two pieces of technology that are redundant with one another forever. When you add a thing that replaces another thing, you should be committing to a plan to replace the old thing. It might be a long term plan. And you should be committing to rewriting the new thing using the old tools if the new tools don’t actually work out. # |

|
So, in closing # |

|
This is what you should do, most of the time. Prefer technology that’s well understood, with failure modes that are known. # |
|
Prefer things that let you focus your attention on what really matters. # |
|
Think about what you’re doing holistically, and pick a few tools that cover your entire problem domain and solve all of your problems with them. The interesting thing here is that none of the tools that you pick may be the “right tool” for any given job. But they can still be the right choice for the total set of jobs. # |

|
It’s important to master the tools that you do pick. # |
|
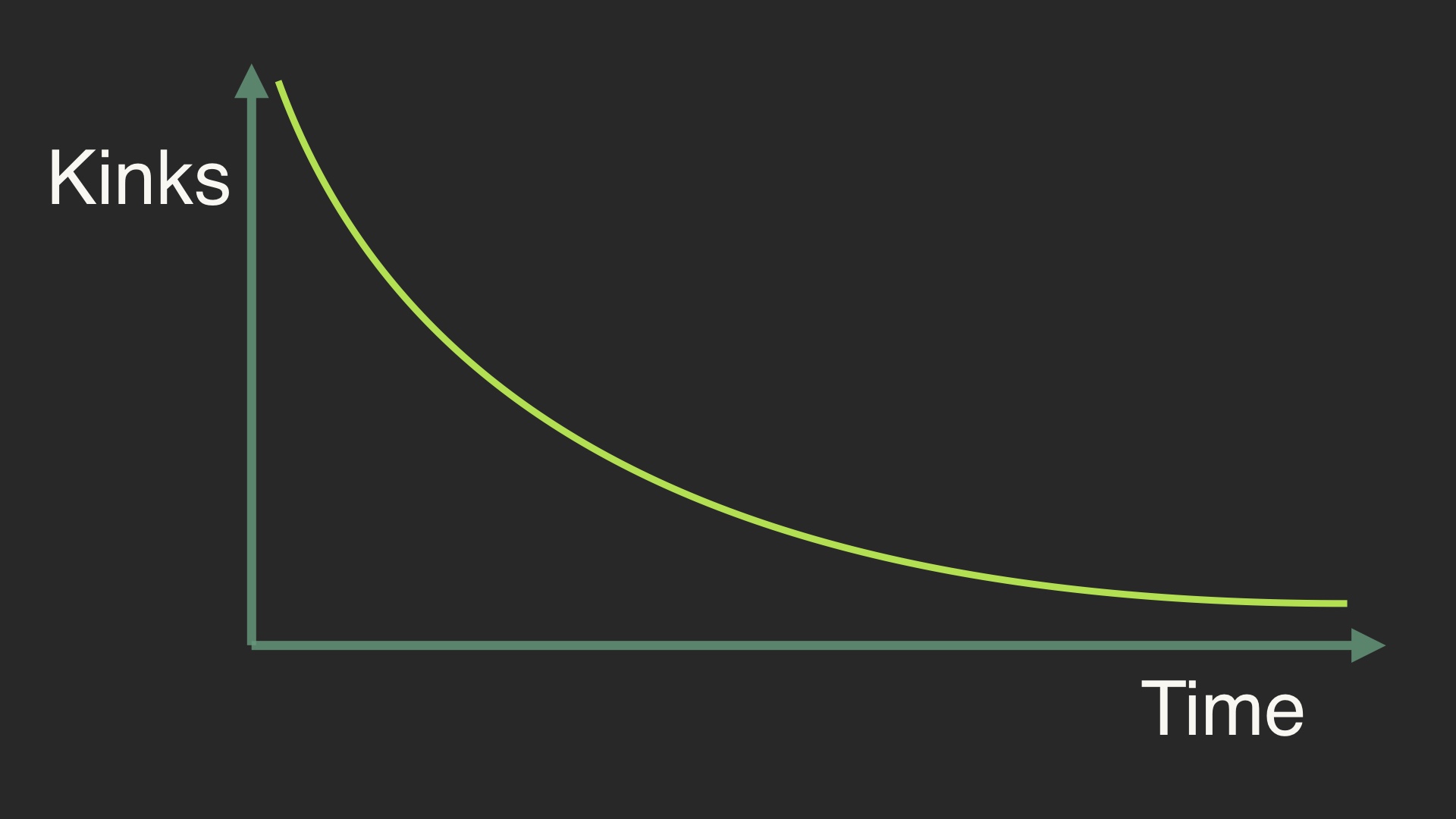
I have noticed that every piece of software obeys this law. When you first start using it, it’s awful. It’s awful because you find all of the problems. # |
|
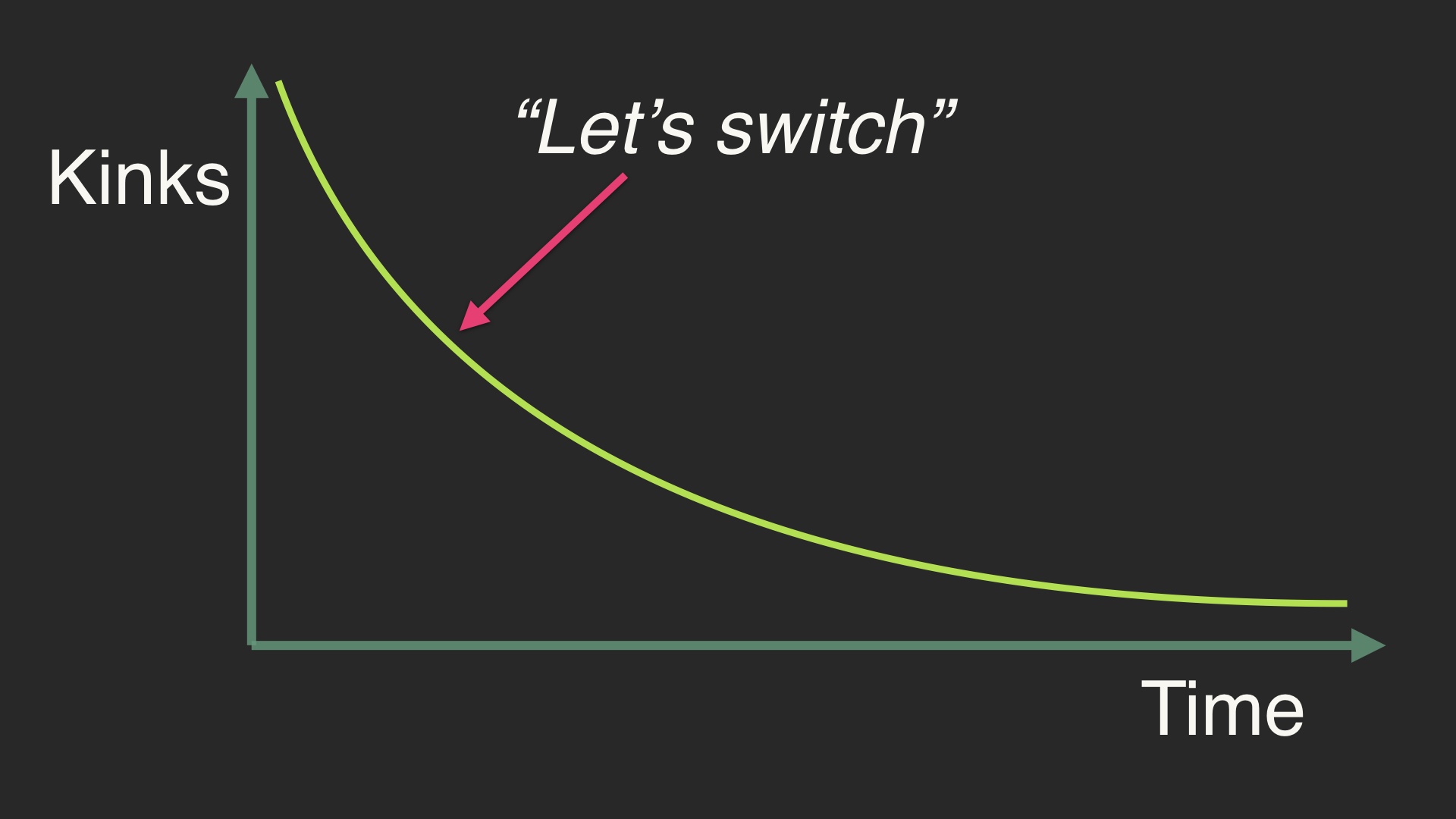
If you are naive, you put a new thing into production, and experience this law in practice. And then you conclude from this that you should use a different thing for the next feature. This is how you awoke one morning, from uneasy dreams probably, and found yourself with nine alerting systems in production. The new thing won’t be better, you just aren’t aware of all of the ways it will be terrible yet. # |
|
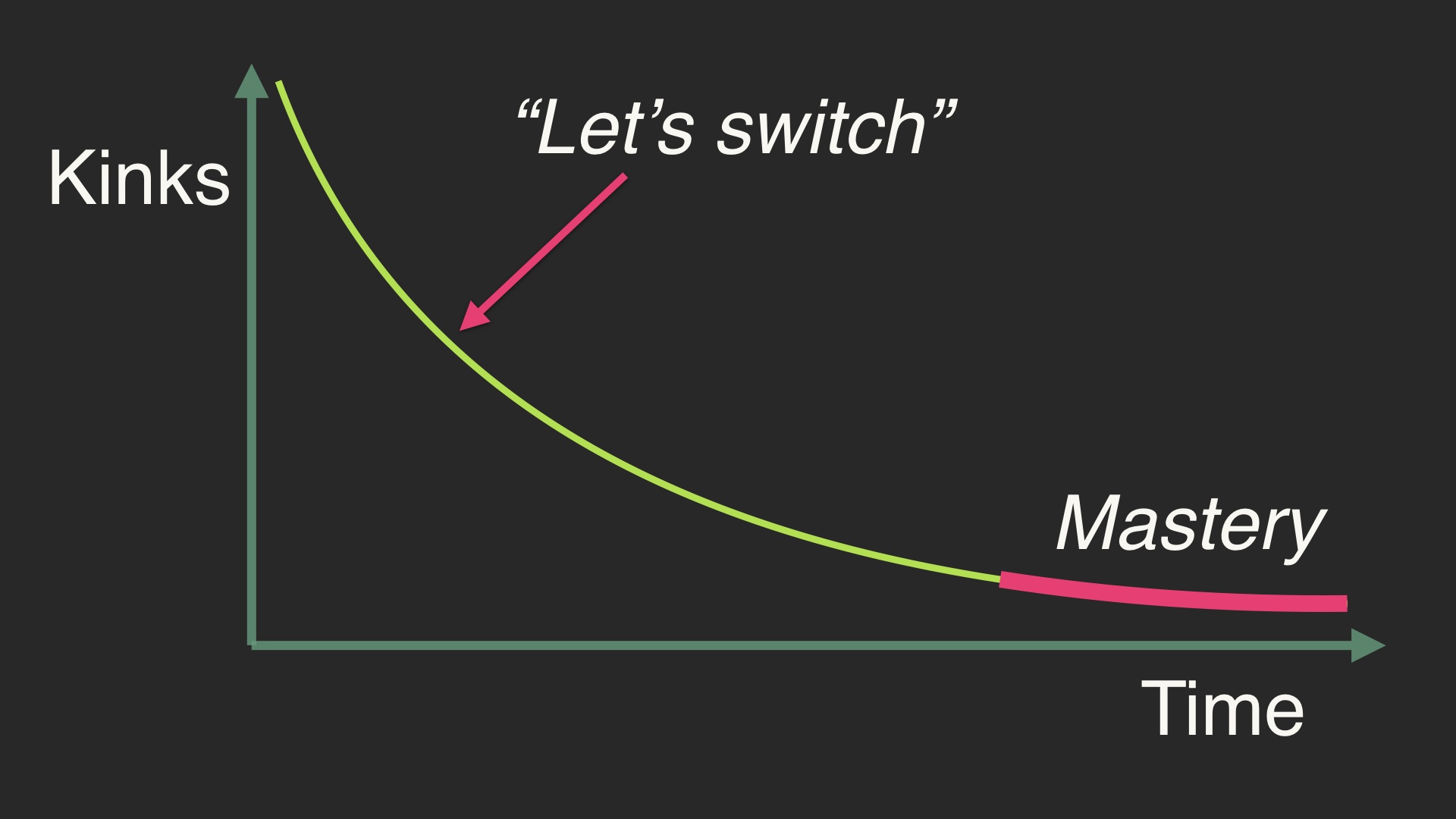
If you behave that way you miss out on the part of the curve that we call “mastery.” That’s a state to the right on this curve, where there are still problems. Everything still sucks but it feels manageable. The grim paradox of this law of software is that you should probably be using the tool that you hate the most. You hate it because you know the most about it. # |

|
You should have a process for adding technology to your stack that involves talking to other humans. # |
|
You should be trying to climb up Maslow’s hierarchy, and worrying about the big picture. You shouldn’t be arguing about what database you’re going to use every single day at work. If you find yourself doing this, try to learn to consider it a sign that something has gone wrong. # |

|
Happiness comes from shipping stuff. # |

|
# |